

注:本文翻译自官网文档 https://docs.pingcap.com/tidbcloud/tidb-x-architecture/
TiDB X 是一种全新的分布式 SQL 架构,它将云原生对象存储作为 TiDB 的核心支柱。此架构目前已在 TiDB Cloud Starter 和 Essential 中提供,能为 AI 时代的工作负载实现弹性扩展、可预测的性能以及优化的总体拥有成本。
TiDB X 代表了从经典的 TiDB 存算一体架构向云原生存算分离架构的根本性演进。通过利用对象存储作为共享的持久化存储层,TiDB X 引入了计算工作负载的分离,将在线事务处理工作负载与资源密集型的后台任务隔离开来。
本文档介绍了 TiDB X 架构,解释了其背后的设计动机,并阐述了相较于经典 TiDB 架构的关键创新。
经典 TiDB 的局限性
本节分析了经典 TiDB 的架构及其局限性,这些局限性催生了 TiDB X 的开发。
经典 TiDB 的优势
经典 TiDB 的存算一体架构解决了传统单体数据库的局限性。通过将计算与存储解耦,并利用 Raft 共识算法,它提供了分布式 SQL 工作负载所需的韧性和可扩展性。
经典 TiDB 架构提供以下基础能力:
-
水平扩展性:支持读写性能的线性扩展。集群可以扩展到每秒处理数百万次查询,并管理跨数千万张表的超过 1 PiB 的数据。
-
混合事务与分析处理:它统一了事务处理和分析工作负载。通过将繁重的聚合和连接操作下推至 TiFlash,它能在新鲜的事务数据上提供可预测的实时分析,而无需复杂的 ETL 流程。
-
非阻塞式模式变更:它采用了完全在线的 DDL 实现。模式变更不会阻塞读写操作,允许数据模型演进,对应用程序延迟或可用性的影响最小。
-
高可用性:支持无缝的集群升级和扩缩容操作。这确保了在维护或资源调整期间关键服务仍然可访问。
-
多云支持:作为开源解决方案,支持亚马逊云科技、谷歌云、微软 Azure 和阿里云。这提供了云中立性,避免了供应商锁定。
经典 TiDB 面临的挑战
尽管经典 TiDB 的存算一体架构提供了高韧性,但本地节点上存储与计算的紧耦合在超大规模环境下也带来了限制。随着数据量增长和云原生需求演进,一些结构性挑战随之显现。
扩展性限制
-
数据移动开销:在经典 TiDB 中,扩容或缩容操作需要在节点间物理移动 SST 文件。对于大型数据集,此过程耗时较长,并且由于数据移动期间消耗大量 CPU 和 I/O 资源,可能降低在线流量性能。
-
存储引擎瓶颈:经典 TiDB 底层的 RocksDB 存储引擎使用由全局互斥锁保护的单 LSM 树。这种设计造成了可扩展性天花板,使系统难以处理大型数据集(例如,每个 TiKV 节点超过 6 TiB 数据或超过 30 万个 SST 文件),阻碍了系统充分利用硬件容量。
稳定性与性能干扰
-
资源争用:繁重的写入流量会触发大量的本地压缩作业以合并 SST 文件。在经典 TiDB 中,由于这些压缩作业运行在为在线流量服务的同一 TiKV 节点上,它们会与在线应用争用相同的 CPU 和 I/O 资源,从而可能影响在线应用。
-
缺乏物理隔离:逻辑 Region 与物理 SST 文件之间没有物理隔离。移动 Region 等操作会产生压缩开销,这些开销直接与用户查询竞争资源,导致潜在的性能抖动。
-
写入限流:在高压写入下,如果后台压缩跟不上前台写入流量,经典 TiDB 会触发流控机制以保护存储引擎。这导致应用程序的写入吞吐量受限和延迟激增。
资源利用率与成本
-
资源过度配置:为了在流量高峰和后台维护期间保持稳定性和确保性能,用户通常基于“高水位线”需求过度配置硬件。
-
扩展不灵活:由于计算与存储耦合,即使用户的 CPU 利用率仍然很低,他们也可能被迫添加昂贵的计算密集型节点,仅仅是为了获得额外的存储容量。
TiDB X 的设计动机
向 TiDB X 的转变源于将数据从物理计算资源中解耦的需求。通过从存算一体架构过渡到存算分离架构,TiDB X 解决了耦合节点的物理限制,以实现以下技术目标:
-
加速扩展:通过消除物理数据迁移的需求,将扩展性能提升高达 10 倍。
-
任务隔离:确保后台维护任务(如压缩)与在线事务流量之间零干扰。
-
资源弹性:实现真正的“按需付费”模式,计算资源可独立于存储容量进行扩展。
关于此架构开发的更多背景,请参阅博客文章 The Making of TiDB X: Origins, Architecture, and What’s to Come。
TiDB X 架构概述
TiDB X 是经典 TiDB 分布式设计的云原生演进。它继承了经典 TiDB 的以下架构优势:
-
无状态 SQL 层:SQL 层无状态,负责查询解析、优化和执行,不存储持久化数据。
-
网关与连接管理:TiProxy 维护持久的客户端连接并无缝路由 SQL 流量。它最初设计用于支持在线升级,现在充当天然的网关组件。
-
基于 Region 的动态分片:TiKV 使用称为 Region 的基于范围的分片单元。数据被分割成数百万个 Region,系统自动管理跨节点的 Region 放置、移动和负载均衡。
TiDB X 通过用云原生共享存储(对象存储)替代本地存算一体存储,演进这些基础。这种转变实现了“计算与计算分离”模型,将资源密集型任务卸载到弹性计算池,以确保即时扩展和可预测的性能。
TiDB X 架构如下:
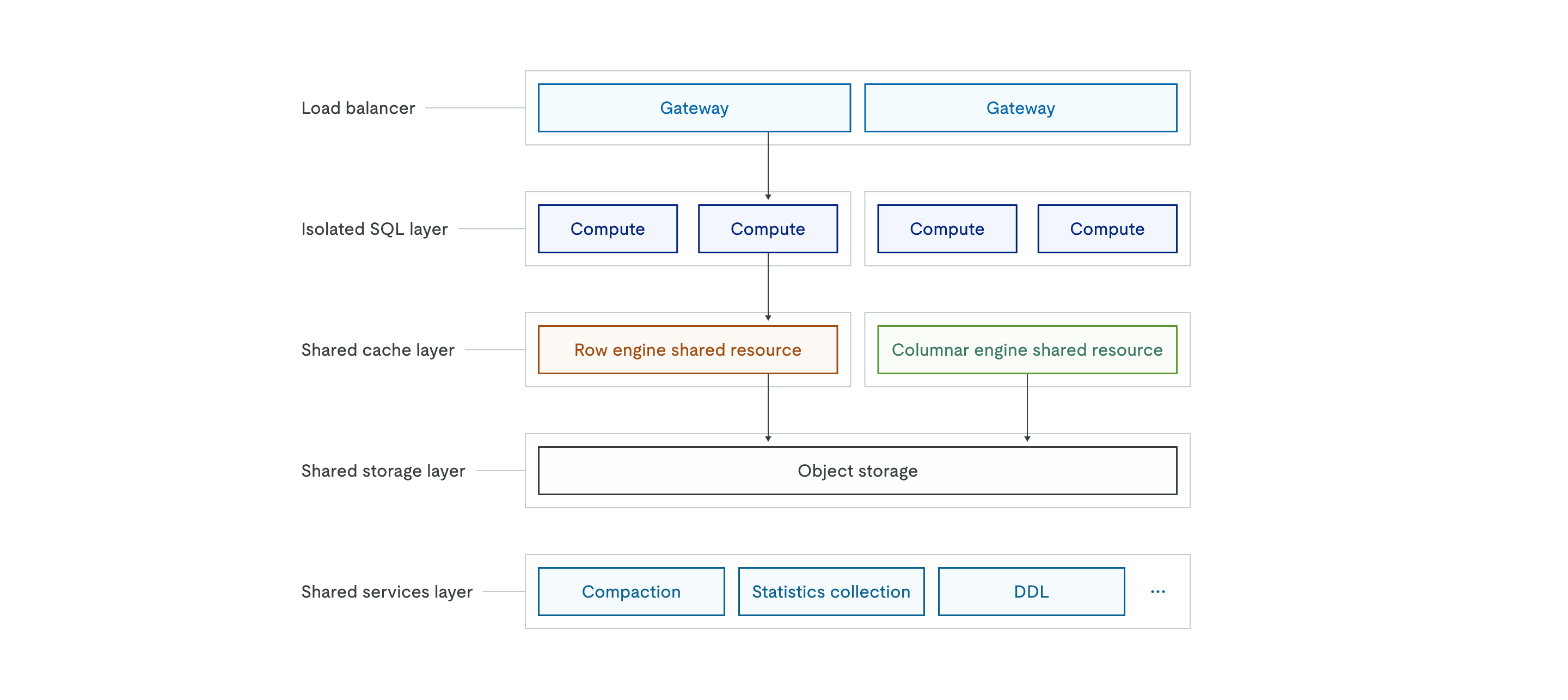
对象存储支持
TiDB X 使用对象存储作为所有数据的单一事实来源。与数据存储在本地磁盘的经典架构不同,TiDB X 将所有数据的持久化副本存储在共享的对象存储层中。上层的共享缓存层充当高性能缓存以确保低延迟。
由于权威数据已存储在对象存储中,备份仅依赖于存储在 S3 中的增量 Raft 日志和元数据,使得备份操作无论总数据量大小都能在几秒钟内完成。在扩容操作期间,新的 TiKV 节点无需从现有节点复制大量数据,而是连接到对象存储并按需加载所需数据,从而显著加速扩容操作。
自动扩缩容机制
TiDB X 架构专为弹性伸缩而设计,由负载均衡器和独立的 SQL 层的无状态特性提供支持。共享缓存层可以基于 CPU 使用率或磁盘容量进行扩展。系统会在几秒钟内自动添加或移除计算 Pod,以适应实时工作负载需求。
这种技术弹性支持基于消耗量的按需付费定价模型。用户不再需要为峰值负载预置资源。相反,系统会在流量高峰时自动扩展,在空闲时段自动缩减,以最小化成本。
微服务与工作负载隔离
TiDB X 实现了精细的职责分离,以确保不同的工作负载不会相互干扰。独立的 SQL 层由独立的计算节点组构成,支持工作负载隔离或多租户场景,不同的应用程序可以使用专用的计算资源,同时共享相同的基础数据。
共享服务层将繁重的数据库操作分解为独立的微服务,包括压缩、统计信息收集和 DDL 执行。通过将资源密集型的后台操作卸载到此层,TiDB X 确保这些操作不会与为在线用户流量服务的计算节点竞争 CPU 或内存资源。这种设计为关键应用程序提供了更可预测的性能,并允许每个组件基于其自身的资源需求独立扩展。
TiDB X 的关键创新
下图并排比较了经典 TiDB 和 TiDB X 的架构。它突出了从存算一体设计到存算分离设计的转变,以及计算工作负载分离的引入。
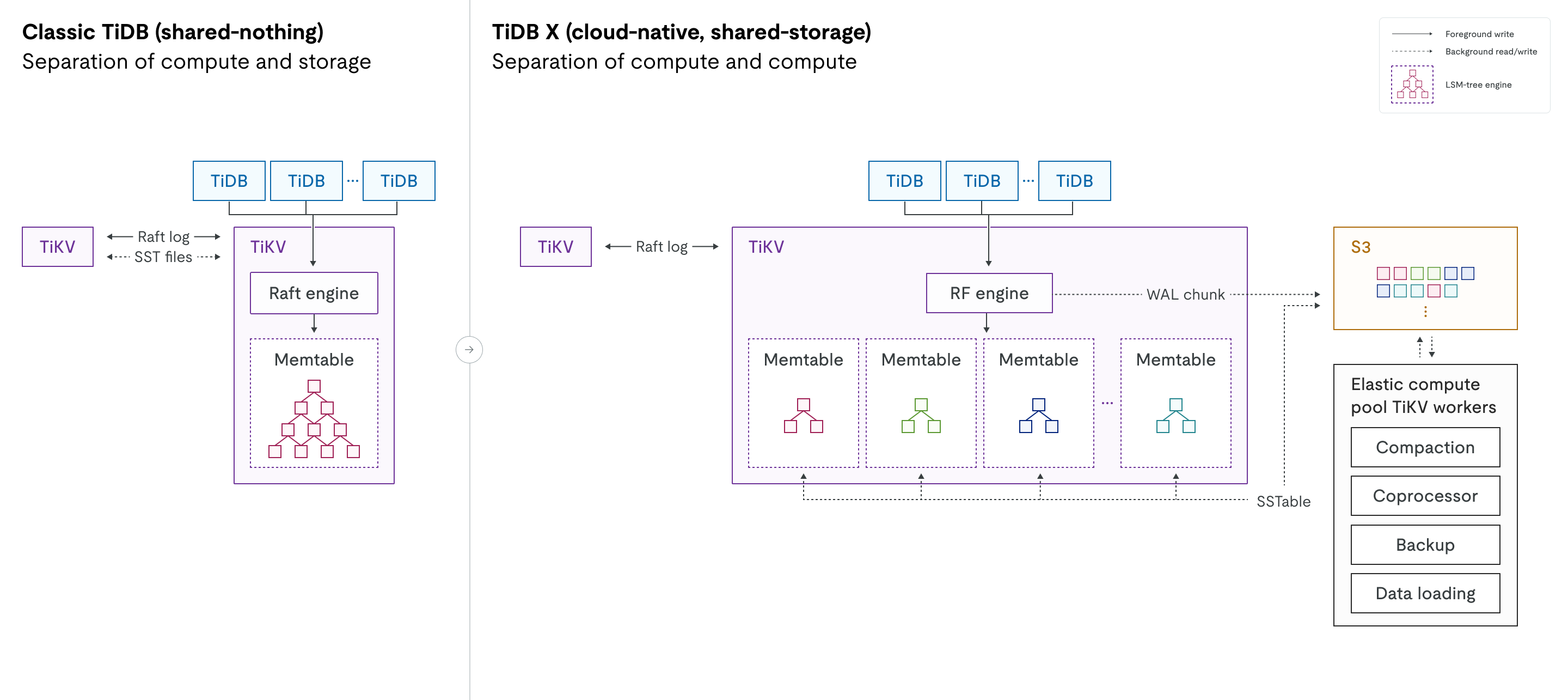
引擎演进:在经典 TiDB 中,Raft 引擎管理多 Raft 日志,而 RocksDB 处理本地磁盘上的物理数据存储。在 TiDB X 中,这些组件被新的 RF 引擎和重新设计的 KV 引擎所取代。KV 引擎是一个 LSM 树存储引擎,替代了 RocksDB。这两个新引擎都针对高性能以及与对象存储的无缝集成进行了专门优化。
计算工作负载分离:图中的虚线表示与对象存储层的后台读写交互。在 TiDB X 中,RF/KV 引擎与对象存储之间的这些交互已与前台进程解耦,确保后台操作不影响在线流量的延迟。
计算与计算分离
虽然经典 TiDB 已经分离了计算和存储,但 TiDB X 在 SQL 层和存储层内部引入了额外的分离层。这种设计区分了用于在线事务工作负载的轻量计算和用于资源密集型后台任务的重量计算。
- 轻量计算:专用于 OLTP 工作负载的资源,例如用户查询。
对于轻量级 OLTP 工作负载,由于重量计算任务被卸载到弹性计算池,服务于用户流量的 TiKV 服务器被专门保留用于在线查询。因此,TiDB X 能以更少的资源提供更稳定和可预测的性能。这种分离确保了后台任务不会干扰在线事务处理。
- 重量计算:一个独立的弹性计算池,用于后台任务,如压缩、备份、统计信息收集、数据加载和慢查询处理。
对于重量计算任务,TiDB X 可以自动调配弹性计算资源,以全速运行这些工作负载,同时对在线流量的影响最小。例如,当您添加索引时,TiDB 工作线程、协处理器工作线程和 TiKV 工作线程会根据数据量动态调配。这些调配的弹性计算资源与处理在线流量的 TiDB 和 TiKV 服务器隔离,确保资源密集型操作不再与关键的 OLTP 查询竞争。在实际场景中,索引创建速度可比经典 TiDB 快高达 5 倍,且不影响在线服务。
从存算一体到存算分离的转变
TiDB X 从经典的存算一体架构转变为存算分离架构。在 TiDB X 中,对象存储,而非本地磁盘,充当所有持久化数据的单一事实来源。这消除了在扩缩容操作期间复制大量数据的需求,并实现了快速的弹性。
转向对象存储不会降低前台读写性能。
-
读操作:轻量级请求由本地缓存和磁盘服务。仅重量级读工作负载被卸载到远程弹性协处理器工作线程。
-
写操作:与对象存储的交互是异步的。Raft 日志首先持久化到本地磁盘,Raft WAL 块在后台上传到对象存储。
-
压缩:当 MemTable 中的数据写满并刷新到本地磁盘时,Region Leader 将 SST 文件上传到对象存储。在弹性压缩工作线程上完成远程压缩后,会通知 TiKV 节点从对象存储加载压缩后的 SST 文件。
弹性 TCO
在经典 TiDB 中,集群通常被过度配置以同时处理峰值流量和后台任务。TiDB X 支持自动扩缩容,允许用户仅为消耗的资源付费。用于重量级任务的后台资源按需调配,并在不再需要时释放,从而消除浪费的成本。
TiDB X 使用请求容量单位来衡量预调配的计算容量。一个 RCU 提供固定量的计算资源,可以处理一定数量的 SQL 请求。您配置的 RCU 数量决定了集群的基线性能和吞吐容量。您可以设置上限以控制成本,同时仍然受益于自动扩缩容。系统将根据需要自动调配额外的弹性计算容量来处理流量高峰或重量级后台任务(如索引创建),并且仅在调配期间计费。
从 LSM 树到 LSM 森林
在经典 TiDB 中,每个 TiKV 节点运行一个 RocksDB 实例,该实例将所有 Region 的数据存储在一个大型 LSM 树中。由于来自数千个 Region 的数据混合在一起,诸如移动 Region、扩容或缩容等操作可能会触发大量的压缩。这会消耗大量的 CPU 和 I/O 资源,并可能影响在线流量。该单一的 LSM 树受全局互斥锁保护。随着数据规模的增长(例如,每个 TiKV 节点超过 6 TiB 数据或超过 30 万个 SST 文件),全局互斥锁的争用加剧会影响读写性能。
TiDB X 通过从单一 LSM 树转向 LSM 森林来重新设计存储引擎。在保留逻辑 Region 抽象的同时,TiDB X 为每个 Region 分配其自己独立的 LSM 树。这种物理隔离消除了在扩缩容、Region 移动和数据加载等操作期间的跨 Region 压缩开销。对一个 Region 的操作仅限于其自身的树,并且没有全局互斥锁争用。
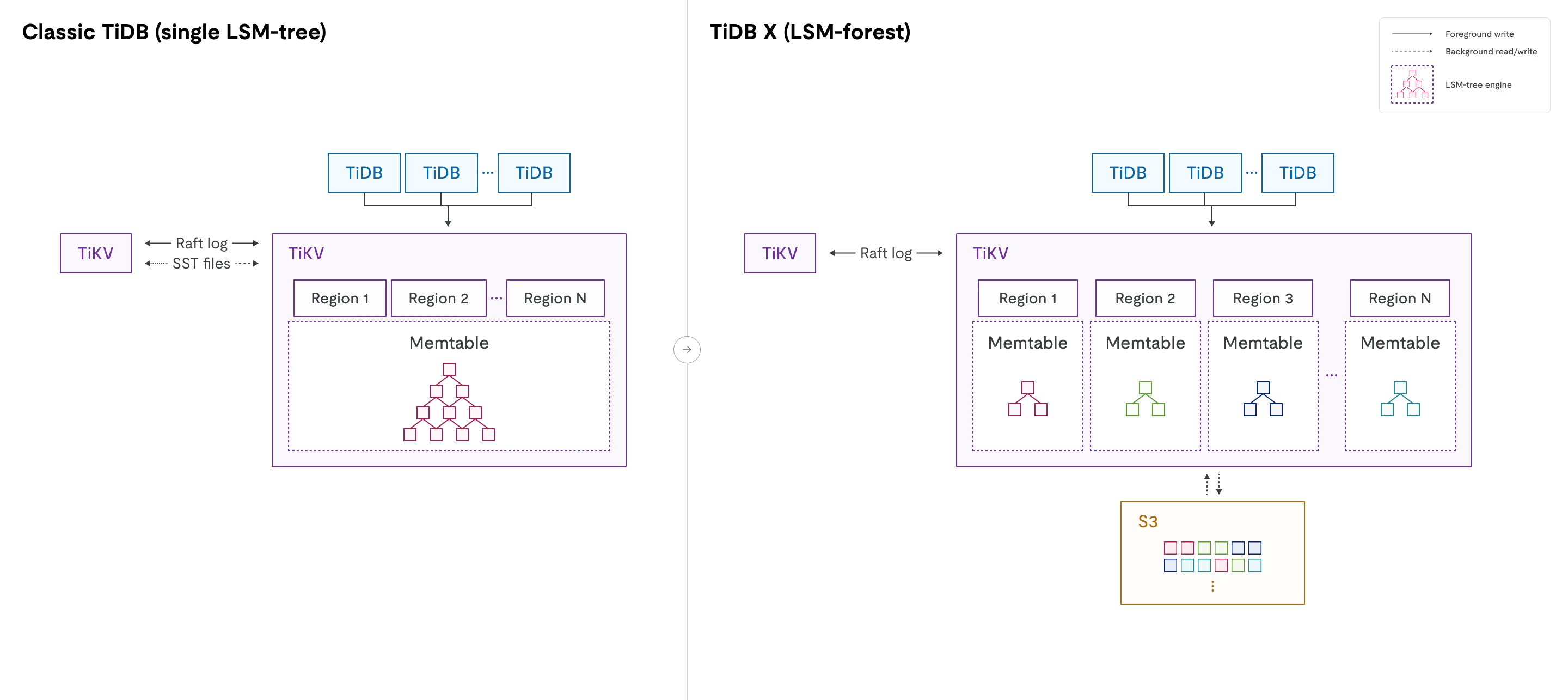
快速弹性扩展
随着数据存储在共享对象存储中且每个 Region 由独立的 LSM 树管理,TiDB X 在添加或移除 TiKV 节点时无需进行物理数据迁移或大规模压缩。因此,扩缩容操作比经典 TiDB 快 5 到 10 倍,同时为在线工作负载保持稳定的延迟。
架构对比总结
下表总结了从经典 TiDB 到 TiDB X 的架构转变,并解释了 TiDB X 如何提高可扩展性、性能隔离和成本效益。
特性 |
经典 TiDB |
TiDB X |
主要优势 (TiDB X) |
架构 |
存算一体(数据存储在本地磁盘) |
存算分离(对象存储作为权威持久化存储) |
对象存储实现了云原生弹性 |
稳定性 |
前台和后台任务共享相同资源 |
计算与计算分离(重量级任务使用弹性计算池) |
在写入密集型或维护工作负载下保护 OLTP 工作负载 |
性能 |
OLTP 与后台任务争用 CPU 和 I/O |
重量级任务使用专用的弹性计算池 |
在重量级任务更快完成的同时,降低 OLTP 延迟 |
扩展机制 |
物理数据迁移(TiKV 节点间复制 SST 文件) |
TiKV 节点仅通过对象存储读取或写入 SST 文件 |
扩容和缩容速度快 5–10 倍 |
存储引擎 |
每个 TiKV 节点使用单一 LSM 树(RocksDB) |
LSM 森林(每个 Region 拥有一个独立的 LSM 树) |
消除全局互斥锁争用,减少压缩干扰 |
DDL 执行 |
DDL 与用户流量争用本地 CPU 和 I/O |
DDL 卸载到弹性计算资源 |
模式变更更快,延迟更可预测 |
成本模型 |
需要为峰值工作负载过度配置资源 |
弹性总体拥有成本(按需付费) |
仅为实际资源消耗付费 |
备份 |
依赖于数据量的物理备份 |
元数据驱动,与对象存储集成 |
备份操作显著加快 |