

v5.0.1 版本tidb 集群故障演练
参考文章:

数据库是每个公司的重中之重,它往往存储了公司的核心数据,一旦出现永久性损坏,对公司的打击会是灾难性的。分布式数据库虽然采用数据多副本备份机制来保证数据的可靠性,但同样也会面临多副本丢失的风险。灾难出现如何快速恢复也是DBA需要面对的问题,本案通过对具体示例的理解与操作介绍了分布式NEWSQL数据库Tidb对多副本丢失问题的处理。 一、TiDB 的整体架构: TiDB 集群主要包括三个核心组件:T…

一篇文章带你玩转TiDB灾难恢复 一、背景 高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。 TiDB TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会…
https://docs.pingcap.com/zh/tidb/stable/tikv-control
演练背景&目标:
目的是打造双云机房部署tidb 集群,在主机房故障时可以紧急使用少数的pd 节点和tikv 节点恢复服务
pd 节点的演练文档: 使用pd-recover 恢复pd 多数节点故障的场景
测试环境部署信息:
A,B 两个机房: 所有的region 的leader 调度到A 机房
使用label 标签保证B 机房的那个tikv 节点拥有完整的数据副本

1.设置标签(如果之前是单机房可通过如下设置新的标签)
» config set location-labels dc,host
» store label 4 dc bjtx
» store label 24045 dc bjtx
» store label 1001 dc bjtx
» store label 22508 dc bjbd
-- 查看store 基本信息
» store --jq=".stores[].store |{id,address,state_name,labels}"
{"id":24045,"address":"172.29.238.197:20174","state_name":"Up","labels":[{"key":"host","value":"tikv4"},{"key":"dc","value":"bjtx"}]}
{"id":4,"address":"172.29.238.238:20174","state_name":"Up","labels":[{"key":"host","value":"tikv1"},{"key":"dc","value":"bjtx"}]}
{"id":1001,"address":"172.29.238.146:20174","state_name":"Up","labels":[{"key":"host","value":"tikv1"},{"key":"dc","value":"bjtx"}]}
{"id":22508,"address":"192.168.149.156:20174","state_name":"Up","labels":[{"key":"host","value":"tikv3"},{"key":"dc","value":"bjbd"}]}
2.使用pd-ctl 将所有region 的leader 调度到bjtx 机房,并通过监控确认所有的region leader 是否都调度到A 机房
» config show label-property
{}
» config set label-property reject-leader dc bjbd
Success!
» config show label-property
{
"reject-leader": [
{
"key": "dc",
"value": "bjbd"
}
]
}
-- 查看bjbd机房是否包含了所有的region副本数据(保证在主机房挂掉后备用机房拥有完整的数据副本)
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(all(.!=22508))}"
模拟tikv 主机房故障(手动快速 kill 主机房的pd 节点以及tikv 节点,并mv 相关数据目录)
pd 服务的恢复见上面链接。在pd 恢复服务之后,进行tikv 的恢复
1.使用tiup 关闭健康的tikv 节点192.168.149.156:20174
2.使用tikv-ctl 对所有 Region 移除掉所有位于故障节点上的 Peer
bin/tiup ctl tikv --db /data/tidb/data/tikv-20174/db unsafe-recover remove-fail-stores -s 24045,4,1001 --all-regions
removing stores [24045, 4, 1001] from configurations...
success
-- 注意此操作需要在每一个健康的tikv 节点上执行该命令。因此需要在每个tikv 节点上部署tikv-ctl 工具
a. 此时reload pd,tikv 是失败的(报错如下图)

b.使用scale-in 操作下线故障的tikv 节点,集群整体状态大致如下图所示。此时reload pd,tikv 还是失败的
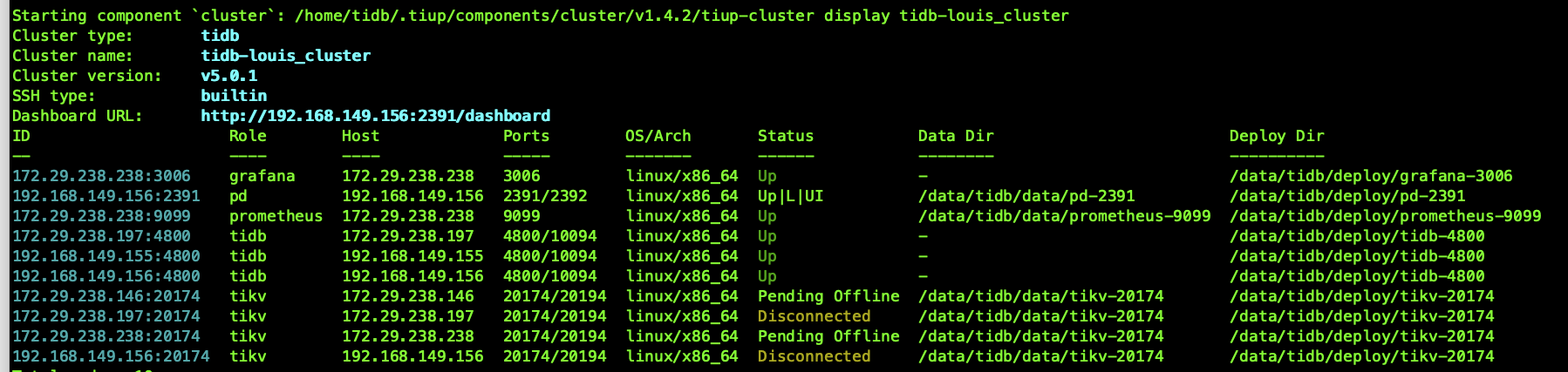
c.使用–force 强制下线故障的tikv 节点(3个)
bin/tiup cluster scale-in tidb-louis_cluster -N 172.29.238.146:20174 --force
......
3.reload pd,tikv
bin/tiup cluster reload tidb-louis_cluster -R=pd,tikv

再次查看监控大盘如下

4.根据实际情况再次扩容tikv,pd 节点