

DR Auto-Sync 用户手册索引
专栏 - 同城双中心自适应同步方案 —— DR Auto-Sync 详解 | TiDB 社区
专栏 - DR Auto-Sync 搭建和灾难恢复手册 | TiDB 社区
专栏 - DR Auto-Sync 的 ACID 恢复功能简介和长期断网应急处理方案 | TiDB 社区
一、版本选择
请在 5.4.0 或更高版本上使用 DR Auto-Sync 功能。
二、前言
DR Auto-Sync 是一种跨同城两中心(网络延迟<1.5ms,带宽>10Gbps)部署的单一集群方案,即两个数据中心只部署一个 TiDB 集群,两中心间的数据复制通过集群自身的 Raft 机制完成。两中心可同时对外进行读写服务,任一中心发生故障不影响数据一致性。

图 1
三、部署 TiDB 集群
3.1 集群部署拓扑
DR Auto-Sync 双活模式部署拓扑如下(示例),需要开启 TiDB 的两个特殊功能:
- Placement-Rules,用以设定每个 TiKV 的角色
Voter - 该 TiKV 上的 replica 可投票、可被选为 leader
Follower - 该 TiKV 上的 replica 可投票,不可被选为 leader
Learner - 该 TiKV 上的 replica 只异步接收日志,不参与投票 - DR Auto-Sync,用以开启两中心自适应同步复制功能
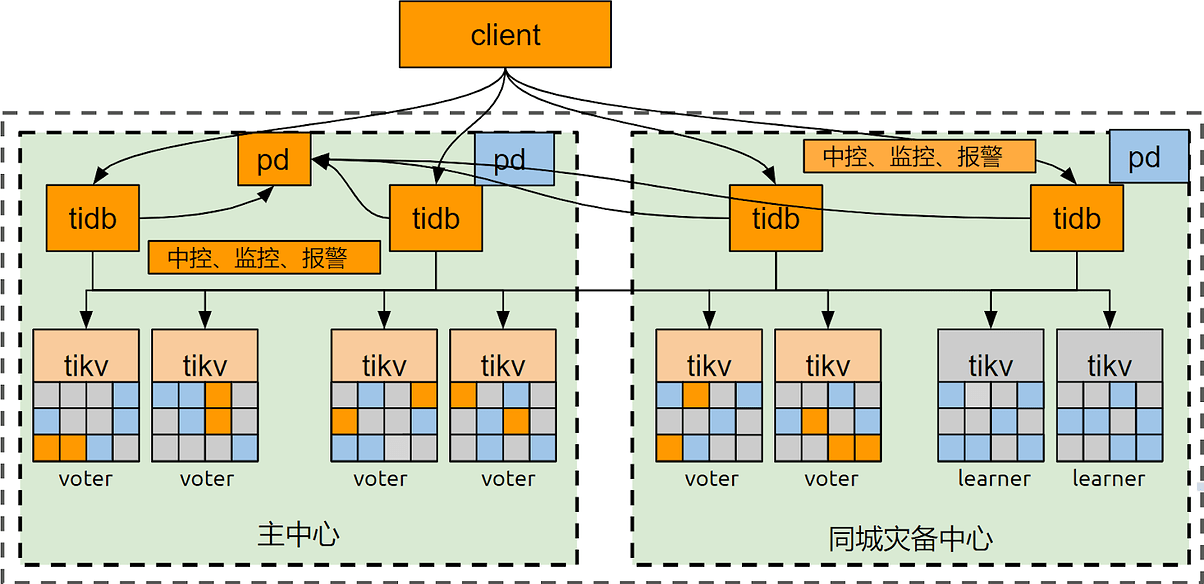
图 2
各台服务器部署的组件如表 1 所示
| 192.168.239.69 | 192.168.239.70 | 192.168.239.71 | 192.168.239.72 |
|---|---|---|---|
| tidb | tidb | tidb | tidb |
| 2*tikv | 2*tikv | 2*tikv | 2*tikv |
| pd | pd | pd | |
| tiup | tiup | ||
| tiup ctl | tiup ctl | ||
| tiup cluster | tiup cluster | ||
| prometheus | prometheus | ||
| alertmgr | alertmgr | ||
| grafana | grafana | ||
| jq | jq |
表 1
3.2 TiKV Label 设计
Placement-Rules 与 DR Auto-Sync 都需要在配置好 Label 的集群上运行。本案例采用双中心 3 Voter 副本 + 1 Learner 副本,共 8 个 TiKV 实例部署,Label 设计如图:
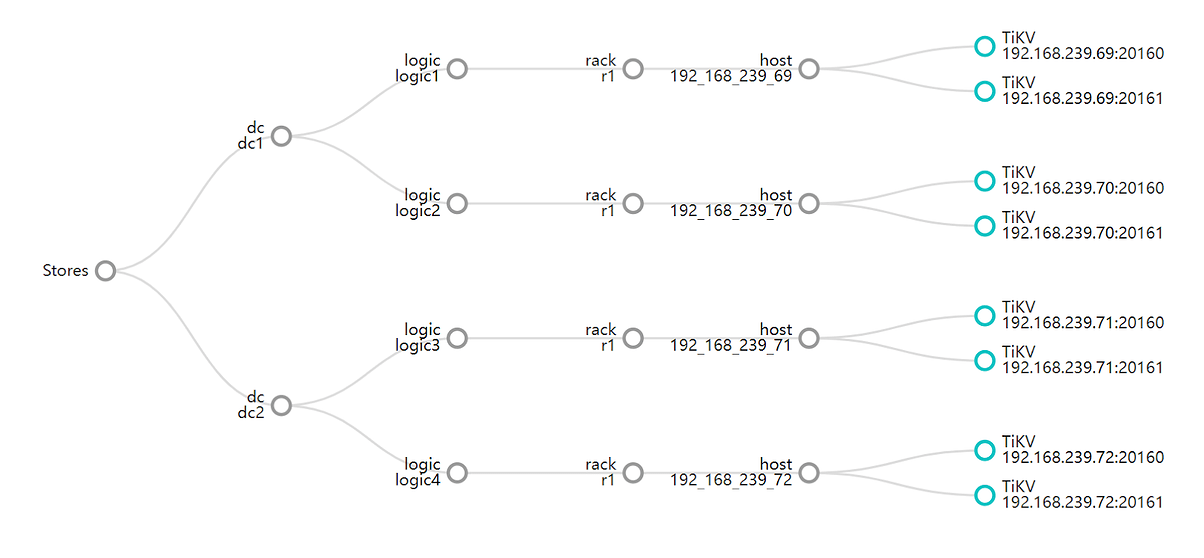
图 3
Label 原理和规划请参考专栏文章: 专栏 - TiDB 集群的可用性详解及 TiKV Label 规划 | TiDB 社区
3.3 拓扑文件示例
global:
user: tidb
ssh_port: 22
deploy_dir: /deploy/sa_cluster_1
data_dir: /data1/sa_cluster_1/
os: linux
arch: amd64
monitored:
node_exporter_port: 39100
blackbox_exporter_port: 39115
deploy_dir: /deploy/sa_cluster_1/monitor-39100
data_dir: /data1/sa_cluster_1/monitor_data
log_dir: /deploy/sa_cluster_1/monitor-39100/log
server_configs:
tidb:
oom-use-tmp-storage: true
performance.max-procs: 0
performance.txn-total-size-limit: 2147483648
prepared-plan-cache.enabled: true
tikv-client.copr-cache.capacity-mb: 10240.0
tikv-client.max-batch-wait-time: 0
tmp-storage-path: /data1/sa_cluster_1/tmp_oom
split-table: true
tikv:
coprocessor.split-region-on-table: true
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: false
server.grpc-compression-type: none
storage.block-cache.shared: true
pd:
enable-cross-table-merge: false
replication.enable-placement-rules: true
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
replication.. -labels: ["dc","logic","rack","host"]
tiflash: {}
tiflash-learner: {}
pump: {}
drainer: {}
cdc: {}
tidb_servers:
- host: 192.168.239.69
ssh_port: 22
port: 4000
status_port: 10080
deploy_dir: /deploy/sa_cluster_1/tidb-4000
- host: 192.168.239.70
ssh_port: 22
port: 4000
status_port: 10080
deploy_dir: /deploy/sa_cluster_1/tidb-4000
- host: 192.168.239.71
ssh_port: 22
port: 4000
status_port: 10080
deploy_dir: /deploy/sa_cluster_1/tidb-4000
- host: 192.168.239.72
ssh_port: 22
port: 4000
status_port: 10080
deploy_dir: /deploy/sa_cluster_1/tidb-4000
tikv_servers:
- host: 192.168.239.69
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /deploy/sa_cluster_1/tikv-20160
data_dir: /data1/sa_cluster_1/tikv_data
config:
server.labels: { dc: "dc1", logic:"logic1", rack:"r1", host:"192_168_239_69" }
- host: 192.168.239.69
ssh_port: 22
port: 20161
status_port: 20181
deploy_dir: /deploy/sa_cluster_1/tikv-20161
data_dir: /data2/sa_cluster_1/tikv_data
config:
server.labels: { dc:"dc1", logic:"logic1", rack:"r1", host:"192_168_239_69" }
- host: 192.168.239.70
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /deploy/sa_cluster_1/tikv-20160
data_dir: /data1/sa_cluster_1/tikv_data
config:
server.labels: { dc:"dc1", logic:"logic2", rack:"r1", host:"192_168_239_70" }
- host: 192.168.239.70
ssh_port: 22
port: 20161
status_port: 20181
deploy_dir: /deploy/sa_cluster_1/tikv-20161
data_dir: /data2/sa_cluster_1/tikv_data
config:
server.labels: { dc:"dc1", logic:"logic2", rack:"r1", host:"192_168_239_70" }
- host: 192.168.239.71
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /deploy/sa_cluster_1/tikv-20160
data_dir: /data1/sa_cluster_1/tikv_data
config:
server.labels: { dc:"dc2", logic:"logic3" , rack:"r1", host:"192_168_239_71" }
- host: 192.168.239.71
ssh_port: 22
port: 20161
status_port: 20181
deploy_dir: /deploy/sa_cluster_1/tikv-20161
data_dir: /data2/sa_cluster_1/tikv_data
config:
server.labels: { dc:"dc2", logic:"logic3" , rack:"r1", host:"192_168_239_71" }
- host: 192.168.239.72
ssh_port: 22
port: 20160
status_port: 20180
deploy_dir: /deploy/sa_cluster_1/tikv-20160
data_dir: /data1/sa_cluster_1/tikv_data
config:
server.labels: { dc:"dc2", logic:"logic4" , rack:"r1", host:"192_168_239_72" }
- host: 192.168.239.72
ssh_port: 22
port: 20161
status_port: 20181
deploy_dir: /deploy/sa_cluster_1/tikv-20161
data_dir: /data2/sa_cluster_1/tikv_data
config:
server.labels: { dc:"dc2", logic:"logic4" , rack:"r1", host:"192_168_239_72" }
pd_servers:
- host: 192.168.239.69
ssh_port: 22
name: pd-192.168.239.69-2379
client_port: 2379
peer_port: 2380
deploy_dir: /deploy/sa_cluster_1/pd-2379
data_dir: /data1/sa_cluster_1/pd_data
- host: 192.168.239.70
ssh_port: 22
name: pd-192.168.239.70-2379
client_port: 2379
peer_port: 2380
deploy_dir: /deploy/sa_cluster_1/pd-2379
data_dir: /data1/sa_cluster_1/pd_data
- host: 192.168.239.72
ssh_port: 22
name: pd-192.168.239.72-2379
client_port: 2379
peer_port: 2380
deploy_dir: /deploy/sa_cluster_1/pd-2379
data_dir: /data1/sa_cluster_1/pd_data
monitoring_servers:
- host: 192.168.239.69
ssh_port: 22
port: 10090
deploy_dir: /deploy/sa_cluster_1/prometheus-10090
data_dir: /data1/sa_cluster_1/prometheus_data
- host: 192.168.239.71
ssh_port: 22
port: 10090
deploy_dir: /deploy/sa_cluster_1/prometheus-10090
data_dir: /data1/sa_cluster_1/prometheus_data
grafana_servers:
- host: 192.168.239.69
ssh_port: 22
port: 3000
deploy_dir: /deploy/sa_cluster_1/grafana-3000
- host: 192.168.239.71
ssh_port: 22
port: 3000
deploy_dir: /deploy/sa_cluster_1/grafana-3000
3.4 备份关键配置
1)集群部署完成后,复制源文件到两个同城容灾中心的 tiup 上
scp -r .tiup/storage/cluster/clusters/sa1/ 192.168.239.71:/home/tidb/.tiup/storage/cluster/clusters/
2)并在两个 tiup 上分别验证是否生效
tiup cluster display sa1
3)在两个中心的服务器上保留原始拓扑文件的备份
3.5 监控组件调整
两个 Grafana 在启动后会都连接到第一个 Prometheus 上,须手工为两个 Grafana 增加增加缺失的灾备中心 Prometheus 数据源。
四、配置并启用 DR Auto-Sync 功能
4.1 使用 jq 查看 TiKV 和 region 关键信息
- 查看 store 基本信息
store --jq=".stores[] | {id: .store.id, address: .store.address, state_name: .store.state_name, capacity: .status.capacity, available: .status.available, region_count: .status.region_count}" - 列出所有 region
region --jq=".regions[] | {id:.id}" - 检查没有 learner peer 的 region
region --jq='.regions[] | select(.peers | any(.role_name=="Learner") | not) | {id: .id, peers: [.peers]}'
4.2 配置 Placement Rules
1)在集搭建后,导入初始数据之前,完成 DR Auto-Sync 的相关配置
config placement-rules rule-bundle save --in="/home/tidb/topology/rules.json"
rules.json 文件内容:
[
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "dc1",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 2,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "dc", "op": "in", "values": ["dc1"]}]
},
{
"group_id": "pd",
"id": "logic3",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 1,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic3"]}]
},
{
"group_id": "pd",
"id": "logic4",
"start_key": "",
"end_key": "",
"role": "learner",
"count": 1,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic4"]}]
}
]
}
]
2)检查配置是否加载
config placement-rules show
3)检查没有 learner peer 的 region
region --jq='.regions[] | select(.peers | any(.role_name=="Learner") | not) | {id: .id, peers: [.peers]}'
4)如过存在尚未转换的 learner peer,参考该命令促进 voter 到 learner 角色的转换(示例)
operator add remove-peer 6066 6
第一个数字为 region id,第二个数字为 store id
4.3 配置 DR Auto-Sync
1)增加 DR Auto-Sync 配置
config set replication-mode dr-auto-sync
config set replication-mode dr-auto-sync label-key dc
config set replication-mode dr-auto-sync primary dc1
config set replication-mode dr-auto-sync dr dc2
config set replication-mode dr-auto-sync primary-replicas 2
config set replication-mode dr-auto-sync dr-replicas 1
2)检查配置是否生效
config show replication-mode
五、计划内切换方案
5.1 停机窗口起始及切换演练的目标拓扑
此处开始的操作有影响交易的可能,需要在停机窗口内进行。
通过 5.2~5.6 章节的操作将集群拓扑转换到下图的状态。
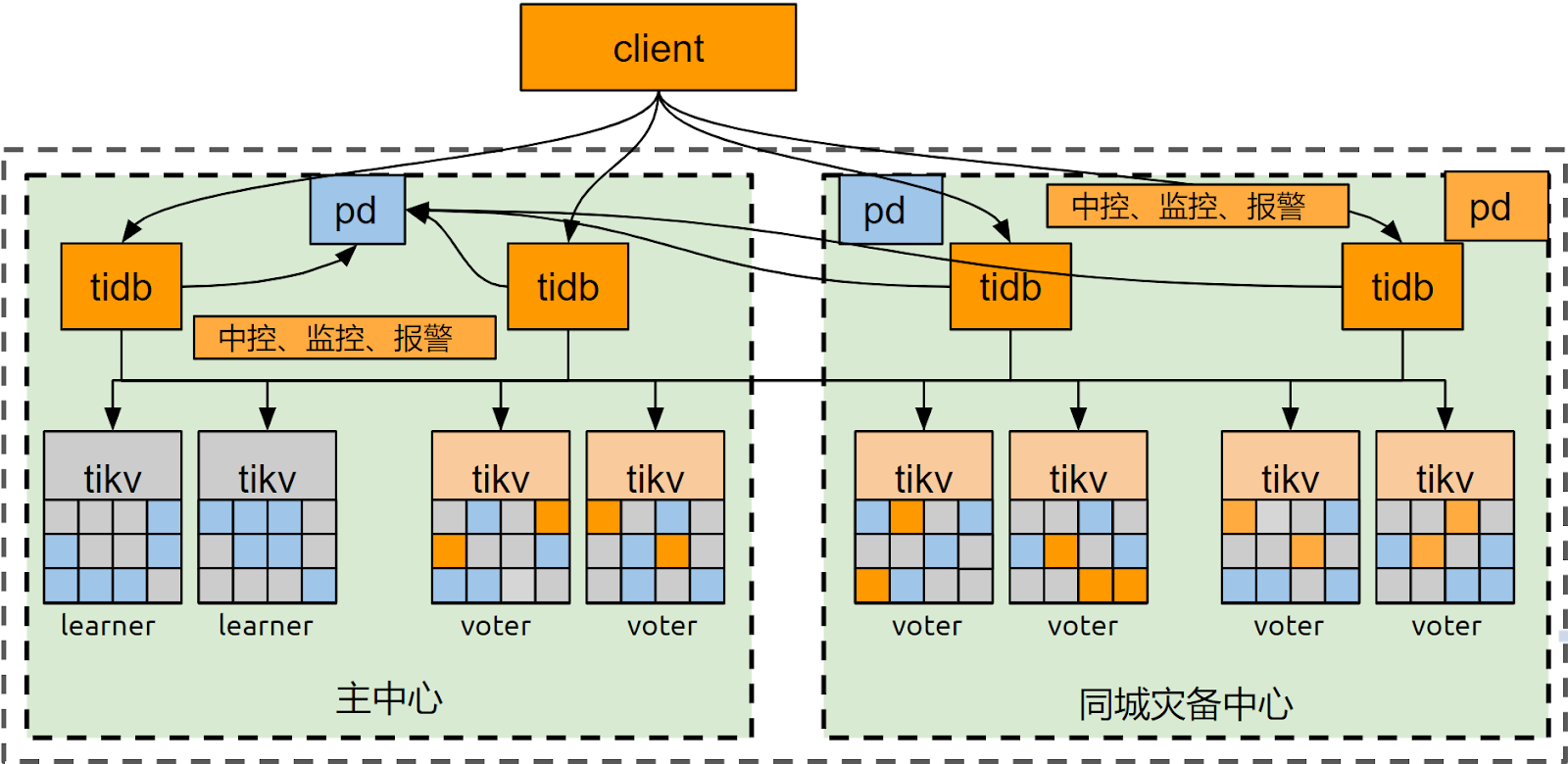
图 4
5.2 在同城容灾中心扩容一个 PD
扩容 PD 到同城容灾中心。下面的命令会刷新所有组件的启动脚本,将新的 pd 加到各个组件的启动脚本中,但不会重启 tidb,tikv 和 pd。因此不会造成集群服务闪断或中止。
tiup cluster scale-out sa1 scale_out_pd.yaml
scale_out_pd.yaml 文件内容:
pd_servers:
- host: 192.168.239.71
ssh_port: 22
name: pd-192.168.239.71-2379
client_port: 2379
peer_port: 2380
deploy_dir: /deploy/sa_cluster_1/pd-2379
data_dir: /data1/sa_cluster_1/pd_data
5.3 手工将 PD leader 切换至同城容灾中心
注意要将 leader 角色切换至集群原有 PD 而不是新扩容的 PD 上,这是为了防止由于元信息注册滞后造成集群不可用的风险(风险详见 官网文档)
1)通过 pd-ctl 操作
member leader transfer pd-192.168.239.72-2379
2)检查 PD Leader 是否已经切换完成
member leader show
5.4 在主中心缩容一个 PD
缩容一个主中心 PD。下面的命令会刷新所有组件的启动脚本,将新的 pd 加到各个组件的启动脚本中,但不会重启 tidb,tikv 和 pd。因此不会造成集群服务闪断或中止。
tiup cluster scale-in sa1 -N 192.168.239.70:2379
5.5 修改 placement-rules,切换主备中心的副本角色
1)在 pd-ctl 中执行
config placement-rules rule-bundle save --in="/home/tidb/topology/rules_reverse.json"
rules_reverse.json 文件内容:
[
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "voters",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 2,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "dc", "op": "in", "values": ["dc2"]}]
},
{
"group_id": "pd",
"id": "voterswoleader",
"start_key": "",
"end_key": "",
"role": "follower",
"count": 1,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic2"]}]
},
{
"group_id": "pd",
"id": "learners",
"start_key": "",
"end_key": "",
"role": "learner",
"count": 1,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic1"]}]
}
]
}
]
2)检查配置是否加载
config placement-rules show
3)检查没有 learner peer 的 region
region --jq='.regions[] | select(.peers | any(.role_name=="Learner") | not) | {id: .id, peers: [.peers]}'
4)通过监控项 TiKV-Details→Cluster→Leader 监测 region leader 是否发生转移,Learner 节点应迁出全部的 ledaer,其 leader 数变为 0。
5)如过存在尚未转换的 learner peer,参考该命令促进 voter 到 learner 角色的转换(示例)
operator add remove-peer 6066 6
5.6 修改 dr auto-sync 配置,切换主备中心角色
1)在 pd-ctl 中执行
config set replication-mode dr-auto-sync primary dc2
config set replication-mode dr-auto-sync dr dc1
2)检查配置是否生效
config show all
3)配置完毕,检查 tikv detail 监控中 leader 分布是否都在 DR 中心的 tikv 上
4)进行计划内切换演练的测试交易或承载生产交易。
如果演练要求主机房完全停机,需要主中心组件全部下线,并确认复制模式转为 async 后,才能承接测试交易或生产交易,确认复制状态的命令:
curl http://127.0.0.1:2379/pd/api/v1/replication_mode/status
5.7 下线组件的拉起及演练完成后的目标拓扑
拉起 5.6 中下线的组件(如有),TiKV 会自动追平数据,DR Auto-Sync 从 async 进入 sync-recover 再进入 sync 状态,等待 sync 后再进行下一步操作。确认复制状态的命令:
curl http://127.0.0.1:2379/pd/api/v1/replication_mode/status
通过 5.8~5.12 章节的操作将集群拓扑转换到下图的状态。
图 5
5.8 将同城容灾中心临时增加的 PD 迁移回主中心
扩容一个 PD 到主中心。下面的命令会刷新所有组件的启动脚本,将新的 pd 加到各个组件的启动脚本中,但不会重启 tidb,tikv 和 pd。因此不会造成集群服务闪断或中止。
tiup cluster scale-out sa1 scale_out_pd.yaml
scale_out_pd.yaml 文件内容:
pd_servers:
- host: 192.168.239.70
ssh_port: 22
name: pd-192.168.239.70-2379
client_port: 2379
peer_port: 2380
deploy_dir: /deploy/sa_cluster_1/pd-2379
data_dir: /data1/sa_cluster_1/pd_data
5.9 手工将 PD leader 切换至主中心
注意要将 leader 角色切换至集群原有 PD 而不是新扩容的 PD 上,这是为了防止由于元信息注册滞后造成集群不可用的风险(风险详见 官网文档)
1)通过 pd-ctl 操作
member leader transfer pd-192.168.239.69-2379
2)检查 PD Leader 是否已经切换完成
member leader show
5.10 缩容掉同城容灾中心临时增加的 PD
缩容掉同城容灾中心临时增加的 PD。下面的命令会刷新所有组件的启动脚本,将新的 pd 加到各个组件的启动脚本中,但不会重启 tidb,tikv 和 pd。因此不会造成集群服务闪断或中止。
tiup cluster scale-in sa1 -N 192.168.239.71:2379
5.11 修改 placement-rules,切换主备中心的副本角色
1)在 pd-ctl 中执行
config placement-rules rule-bundle save --in="/home/tidb/topology/rules.json"
rules.json 文件内容:
[
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "voters",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 2,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "dc", "op": "in", "values": ["dc1"]}]
},
{
"group_id": "pd",
"id": "voterswoleader",
"start_key": "",
"end_key": "",
"role": "follower",
"count": 1,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic3"]}]
},
{
"group_id": "pd",
"id": "learners",
"start_key": "",
"end_key": "",
"role": "learner",
"count": 1,
"location_labels": ["dc", "logic", "rack", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic4"]}]
}
]
}
]
2)检查配置是否加载
config placement-rules show
3)检查没有 learner peer 的 region
region --jq='.regions[] | select(.peers | any(.role_name=="Learner") | not) | {id: .id, peers: [.peers]}'
4)通过监控项 TiKV-Details→Cluster→Leader 监测 region leader 是否发生转移,Learner 节点应迁出全部的 ledaer,其 leader 数变为 0。
5)如过存在尚未转换的 learner peer,参考该命令促进 voter 到 learner 角色的转换(示例)
operator add remove-peer 6066 6
5.12 修改 dr auto-sync 配置,切换主备中心角色
1)在 pd-ctl 中执行
config set replication-mode dr-auto-sync primary dc1
config set replication-mode dr-auto-sync dr dc2
2)检查配置是否生效
config show all
3)配置完毕,检查 tikv detail 监控中 ledaer 分布是否都在主中心的 tikv 上
4)执行测试交易确认数据库可用
5.13 停机窗口结束
切换演练结束,停机窗口解除。