

1 概述
TiKV 底层存储引擎使用 RocksDB ,RocksDB 是一个基于 LSM tree 的单机嵌入式数据库, 对于LSM Tree 来说compaction是个非常重要的操作,本文对TiKV中涉及的compaction相关内容进行了整理总结。
2 为什么需要 compaction ?
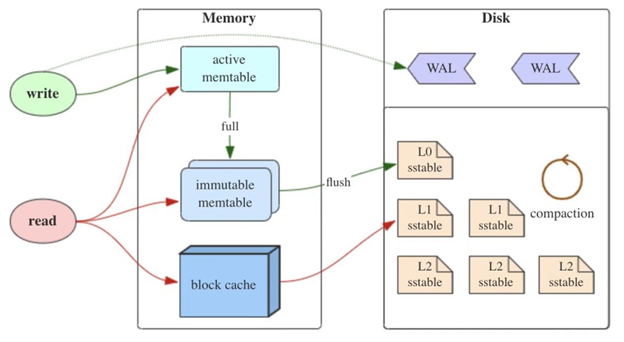
LSM Tree 通过将所有的数据修改操作转换为追加写方式:对于 insert 直接写入新的kv,对于 update 则写入修改后的kv,对于 delete 则写入一条 tombstone 标记删除的记录。通过这种方式将磁盘的随机写入转换为顺序写从而提高了写入性能,但不能进行 in-place 更新,由此带来了以下问题:
1、 大量的冗余和无效数据占用磁盘空间,造成空间放大。
2、 读取数据时如果内存中没有的话,需要从L0层开始进行查找sst file,造成读放大。
因此通过 compaction 操作将数据下层进行合并、清理已标记删除的数据降低空间放大、读放大的影响。但是compaction 又带来了写放大的问题,因此不同的数据库根据需要使用不同的compact 策略,以达到读、写、空间最优的平衡。Compaction属于资源密集型操作,需要读写大量的数据并进行排序,消耗较多的IO、CPU资源。
3 Compaction做什么?
RocksDB的compaction 包含2方面:一是memtable写满后flush到磁盘,这是一种特殊的compacttion,也称为minor compaction。二是从L0 层开始往下层合并数据,也被称为major compaction,也是常说的compaction。
Compaction 实际上就是一个归并排序的过程,将Ln层写入Ln+1层,过滤掉已经delete的数据,实现数据物理删除。其主要过程:
1、 准备:根据一定条件和优先级等从Ln/Ln+1层选择需要合并的sst文件,确定需要处理的key范围。
2、处理:将读到key value数据,进行合并、排序,处理不同类型的key的操作。
3、写入:将排序好的数据写入到Ln+1层sst文件,更新元数据信息。
4 Compaction有哪些常见算法?
以下几种算法是学术性的理论算法,不同的数据库在具体实现时会有优化调整
- Classic Leveled
由O'Neil 在 LSM tree 论文中第一次提出,该算法中每层只有一个Sorted-Run(每个sorted-run 是一组有序的数据集合) , 以分区方式包含在多个文件内,每一层大小是上一层的固定倍数(叫fanout)。合并时使用all-to-all方式, 每次都将Ln的所有数据合并到Ln+1层,并将Ln+1层重写,会读取Ln+1层所有数据。 RocskDB使用some-to-some方式每次合并时只读写部分数据。
- Leveled-N
和上面Classic Leveled 类似,不过每层可以有N个Rorted-Run,每层的数据不是完全有序的。
- Tiered
Tiered 方式同样每层可以包含多个Sorted-Run ,Ln 层所有的数据向下合并到Ln+1层新的Sorted-Run,不需要读取Ln+1层原有的数据。Tiered方式能够最大的减少写放大,提升写入性能。
- FIFO
只有1层,写放大最小,每次compaction删除最老的文件,适合于带时间序列的数据。
RocksDB中compaction 算法支持Leveled compaction、Universal compaction、FIFO compaction。 对于Leveled compaction实际上是 tiered+leveled组合方式(后续描述均为此方式),Universal compaction 即 tiered compaction。
RocksDB的leveled compaction中 level 0包含有多个sorted-run,有多个sst文件,之间存在数据重叠,在compaction时将所有L0文件合并到L1层。对于L1-Lmax 层,每一层都是一个有序的Rorted-Run,包含有多个sst file。在进行读取时首先使用二分查找可能包含数据的文件,然后在文件内使用二分查找需要的数据。
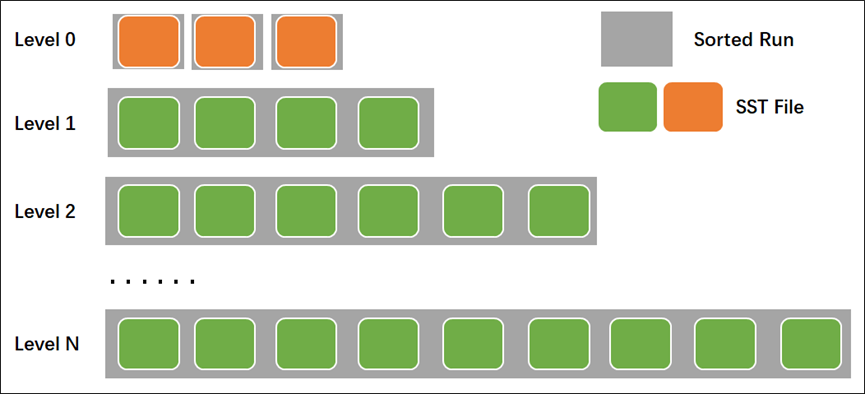
在TiKV 内可使用compaction-style参数修改每个CF的compaction 算法,支持的选项值包括0- level compaction(默认)、1-universal compaction 、2- FIFO,而Level总层数可通过参数num-levels控制,默认为7层。
5 ColumnFamily和SST file的关系?
RocksDB内使用Column Family(CF) 来进行数据的逻辑隔离,CF内可以使用不同的key,每个CF使用不同的memtable和sst文件,所有的 CF 共享WAL、Manifest。每个 CF 的memtable flush时都会切换WAL,其他的CF也开始使用新的WAL,旧的WAL要保证里面所有CF的数据都被flush后才能删除。
在RocskDB内每个Column Family都分配了一个ID,在SST文件有Column Family ID,默认L1层sst file的大小由参数target-file-size-base决定,L2-Lmax的sst文件大小为target-file-size-base*target_file_size_multiplier (默认为1), TiDB内支持参数target-file-size-base,默认为8M。
经过CF的逻辑划分后类似结构如下:
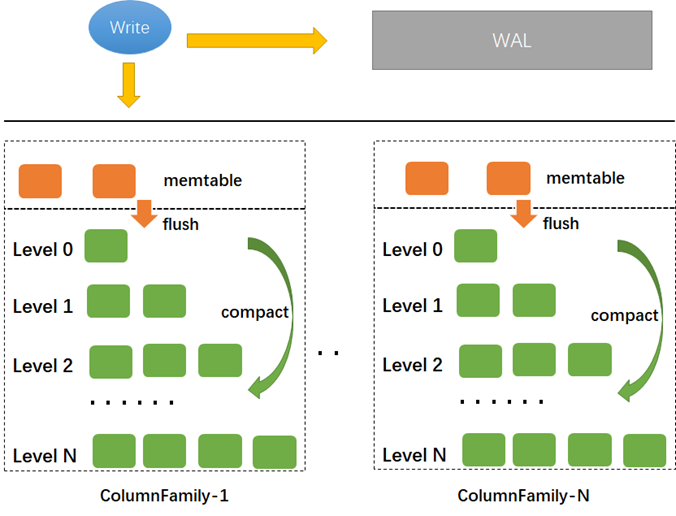
在TiDB中存在2个rocksdb实例,一个用于存储实际的用户数据,称为kv db,另一个用于存储raft log,叫做raft db(6.1.0版本开始raft db 默认被raft egine取代)。kv db 有4个CF:default、write、lock、raft ,raft db只有一个default CF。
6 什么时候触发compaction ?
RocksDB的 compaction 由后台线程 BGWorkCompaction 进行调度。该线程的触发一般有手动触发和自动触发两种情况:
- 手动触发
RocksDB 提供CompactRange、CompactFiles等接口允许用户手动compaction,从而使用户能根据自己的场景触发compaction。
- 自动触发
当WAL切换或memtable被写满后会调用检查是否需要进行compaction,具体如下:
1、 Memtable达到write-buffer-size(TiKV内默认128M)参数大小时会转换为immtuable memtable 等待flush到磁盘,并开启一个新的memtable用于写入。
2、 Memtable flush 时会导致WAL 切换,同时当 WAL 大小达到max-total-wal-size(TiKV默认4G) 时也会进行切换。
3、 当达到如下条件时则调度compaction线程执行compact操作。
(1) sst文件设置以下标记时:达到ttl时间、达到定期compaction时间、已被标记为compaction等。
(2) 遍历所有level,计算每层的score,如果score>1,则需要compaction,当有多个level都达到触发条件时,会选择score最大的level先进行compact。score计算方法如下:
L0层:当前L0 sst文件数和level0-file-num-compaction-trigger参数比例。
L1层:Ln层总大小(不包含正在compact的文件)和max-bytes-for-level-base*max-bytes-for-level-multiplier^(N-1)的比例。
除了上面的条件触发方式外,RocksDB使用BottomMost Recompaction对最底层的delete记录进行再次检查和清理:当某个操作执行时其快照引用的文件位于最底层时,如果包含很多delete则这些delete的数据不能通过正常的compact方式清理掉,因此在操作执行完后release snapshot时重新检查bottommost level ,确定哪些文件可以被compact,comapct后生成的文件仍位于最底层。
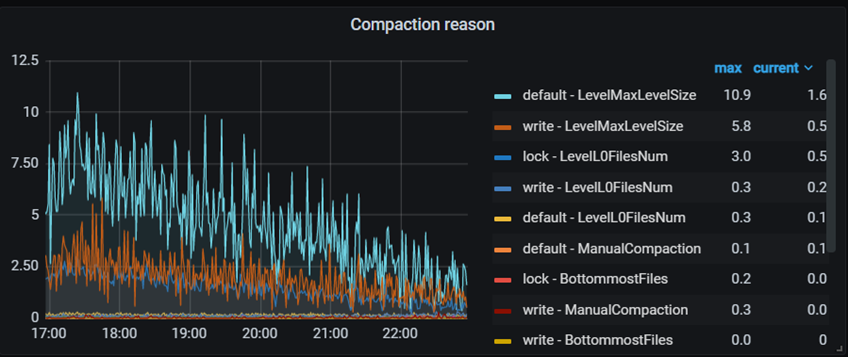
自动compaction可通过disable-auto-compactions 参数关闭,从而可以让用户只使用自定义的compaction 策略,TiKV内同样支持该参数设置。Compaction 的触发原因可通过监控TiKV Detail –> RocksDB KV/ RocksDB raft -> Compaction reason查看。
7 Compaction时选择那些文件?
当选定需要compaction的Ln层后便需要决定需要向下层合并哪些文件,在选择需要合并的文件时主要考虑2方面:文件优先级和范围边界。
- 文件优先级
选择优先级最高的文件进行合并,如果该文件正被其他线程进行合并,则按照优先级依次往下选择。目前有4种优先级策略,在tikv内可通过参数compaction-pri设置,可选值
0 (ByCompensatedSize),1 (OldestLargestSeqFirst),2 (OldestSmallestSeqFirst),3 (MinOverlappingRatio)。
1、 ByCompensatedSize
优先选择包含delete做多的文件,越早删除的数据就越早compact,减少空间放大和读放大
2、 OldestLargestSeqFirst
优先选择最后更新时间最早的文件,将文件上的冷数据合并到下一层,相对热数据留在上一层,减少读放大。 TiKV 的 lockcf默认使用该策略。
3、 OldestSmallestSeqFirst
优先选择包含最老数据的文件,通常有较大key范围数据长时间未向下合并,与下层的key重叠较少,减少写放大。
4、 MinOverlappingRatio
优先选择和下层key重叠率最小的文件,TiKV 的 defaultcf 、writecf 的默认使用策略。
- 范围边界
通过文件优先级选定文件后还要考虑文件的key范围,扩大需要compact的文件范围,如下5个文件,如果在f3优先级最高,则在compact时同时将{f2,f3,f4} 3个文件向下合并,因为f2、f4中key范围与f3有重叠,因此compact的key范围由[k4,k6]扩展到了[k3,k8]。如果选择的文件中有任何文件在被compact则会终止compact文件选择过程。

对于Ln+1层需要按照上述方式对与Ln层有重叠key范围的文件进行扩展,然后将Ln、Ln+1选择的文件内的key作为input数据进行归并排序、清理冗余数据后写入Ln+1 层。如果Ln 层要compact的文件与下层无重叠,则直接将该文件移动到Ln+1层。
为了限制每次compaction的量大小,RocksDB支持通过max_compaction_bytes参数限制每轮compact的大小,该参数仅限制input level的大小,TiKV内支持该参数配置
8 L0 层文件堆积后如何处理?
当有大量数据写入时,如果L0 到 L1 的compaction速度来不及处理会导致L0层文件逐渐累积增多,通过subcompact并行方式可提升L0层compact速度。当L0层文件数量达到一定数量后则会引起write stall,文件数量达到level0-slowdown-writes-trigger 后 会降低写入速度,当达到level0-stop-writes-trigger后则完全停止写入。
当L0 向L1 层合并时,如果L1层的sst file正在往 L2层合并被锁住,将导致本次L0 -> L1层的compact不能执行,因此造成L0层文件不能及时清理。基于此RocksDB引入了intra-L0 compaction,即在发生上述情况时在L0层内部进行compact,将多个sst file合并为1个大的sst file,以此减少L0层文件数量,在一定程度上能够提升L0层的读性能和减少write stall的发生。
9 如何设置compaction并发线程数?
- Flush & Compaction
Flush线程和Compaction线程是RocksDB的2类后台线程 ,使用线程池方式管理,在memtable写满或WAL切换时检查是否需要flush或compaction,如果需要则从线程池里调度线程完成flush或compaction。
默认情况下RocksDB(5.6.1版本)对flush 和 compaction线程池统一进行管理,通过Options::max_background_jobs选项可设置后台线程最大数量,RocksDB会自动调整flush和compaction线程数量。仍可以通过Options::max_background_flushes和Options::max_background_compactions选项设置flush和compact线程的数量。flush线程由于其关键性会放入HighPriority线程池,而compact线程放入LowPriority线程池。
TiKV内提供了参数max-background-jobs、max-background-flushes可用于调整Options::max_background_jobs和Options::max_background_flushes,TiKV 会根据上述参数值计算compact线程数量。TiKV内线程数默认计算如下:
max_background_jobs = MAX(2, max-background-jobs参数)
max_flushs = MIN(max_background_jobs+ 3) / 4, max_background_flushes)
max_compactions = max_background_jobs - max_flushs
- SubCompaction
由于L0层文件由memtable flush生成文件之间存在重叠,不能以sst file为最小分组单位进行并发compaction,因此通过单线程将L0所有文件都合并到L1层。L0 to L1的并发合并使用subcompaction方式:
(1) 首先获取L0层和L1层涉及的每个sst文件的smallest key/largest key
(2) 将这些Key去重排序,每2个key分为一组作为一个range,预估key范围覆盖的sst文件的总大小sum。
(3) 根据参数max_subcompaction、range的数量、sum/4.0/5/max_file_size中的最小值决定subcompaction线程数量。
(4) 将range分配给每个线程,每个线程只处理文件的一部分key的compact,最后compact主线程将subcompact线程的结果进行合并整理。
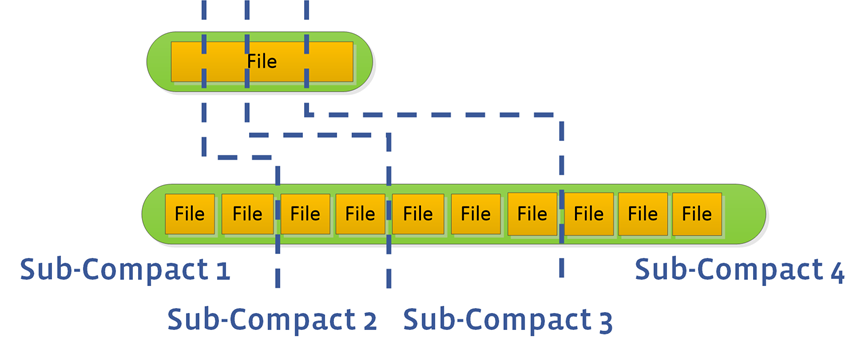
在TiKV内可通过参数max-sub-compactions设置subcompaction的最大并发线程数,kv db默认为3,raft db默认为2。SubCompact线程数量不受max-background-jobs限制,但TiKV内设置的默认数量受max_compaction线程数影响,计算方式为:max_sub_compactions =MAX(1,MIN(max_sub_compactions参数, (max_compactions - 1)))。
除了L0 -> L1 compact时可使用subcompaction外,在manual compaction(leveled compction)时L1+层也使用subcompaction以加快速度。
10 SST文件什么时候删除?
RocksDB使用version来表示数据库的当前状态(即某一时刻sst文件的集合),每当增加或删除一个sst file时都会对Manifest增加一条version edit记录。当执行查询或修改时会引用当前version,同时会对该version下的sst file设置reference count。
Compact完成后会在output level生成新的文件,同时需要删除旧的Input 文件,如果仍有其他操作在compact后仍未执行完成,则在compact后不能立即将需要的文件删除,等到sst file的reference count降为0后才能将文件真正的删除。
11 Compaction Guard
如前面介绍,在compact选择文件时由于key范围重叠,因此会扩展选定的sst 文件,以包含进所有需要的Key,由此会造成的问题是需要额外读写一些多余的key,同时由于一个sst file里可能包含有多个不同的key,在对某段范围key删除后不方便直接删除sst file。
Comapction Guard 是根据key将sst文件分隔成一个个具有指定边界的小文件,从而降低compaction时读写key数量和方便物理删除sst file。
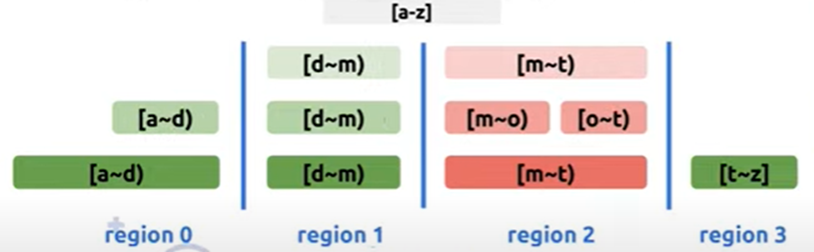
TiKV利用RocksDB的 SST Partitioner接口实现compaction guard,在compact时将sst file 按照region的 end key进行切分,实现了大部分的region和sst file对应,只对kv db的default CF、write CF有效,通过按region 切分sst file后可以实现sst file的快速删除,也能提升region迁移速度。
该功能默认启用通过参数enable_compaction_guard设置,当启用后 使用compaction-guard-max-output-file-size覆盖target-file-size-base的参数值。如果sst file大小小于compaction-guard-min-output-file-size(默认8M)或大于compaction-guard-maxt-output-file-size时都不会触发compaction guard进行切分。
12 TiDB内有哪些场景触发Compaction?
和RocksDB类似TiDB内也有自动和手动compaction,不过无论是自动还手动都是通过调用RockDB的manual compaction函数在RocksDB内产生一次手动compact。
- 自动compaction
对于wirte/default cf,每隔region-compact-check-interval(默认5分钟)时间,就会检查是否需要触发手动RocskDB 的compact,如果一个region中tombstone key数量超过region-compact-min-tombstones (默认10000)并且tombstone key数量超过Key数量的region-compact-tombstones-percent(默认30%),则会触发tikv的自动compaction,每次会检查region-compact-check-step(默认100)个region,tikv会调用RockDB的manual compaction函数CompactRange 在RocksDB内产生一次手动compact。
对于lockcf 每隔lock-cf-compact-threshold(默认10分钟),如果lockcf的数据量达到lock-cf-compact-threshold则会调用RockDB的manual compaction函数。
- 手动compaction
手动compaction是指使用tikv-ctl 命令执行的compact。具体可参考TiDB官方文档tikv-ctl工具介绍。
tikv-ctl --host tikv_ip:port compact -d kv -c default
tikv-ctl --host tikv_ip:port compact -d kv -c write --bottommost force
13 WriteStall有哪些触发场景
当RocksDB的flush或compact 速度落后于数据写入速度就会增加空间放大和读放大,可能导致磁盘空间被撑满或严重的读性能下降,为此则需要限制数据写入速度或者完全停止写入,这个限制就是write stall, write stall触发原因有:1、 memtable数量过多 2、L0文件数量过多 3、 待compact的数据量过多。
- memtable数量过多
当memtable数量达到min-write-buffer-number-to-merge(默认值为1)
参数个时会触发flsush,Flush慢主要由于磁盘性能问题引起,当等待flush的memetable数量达到参数max-write-buffer-number时会完全停止写入。当max-write-buffer-number>3且等待flush的memetable数量>=参数max-write-buffer-number-1时会降低写入速度。
当由于memtable数量引起write stall时,内存充足的情况下可尝试调大max-write-buffer-number、max_background_jobs 、write_buffer_size 进行缓解。
- L0数量过多
当L0 sst文件数达到level0_slowdown_writes_trigger后会触发write stall 降低写入速度,当达到level0_stop_writes_trigger则完全停止写入。
当由于memtable数量引起write stall时,内存充足的情况下可尝试调大max_background_jobs 、write_buffer_size、min-write-buffer-number-to-merge进行缓解。
- 待compact的数据量过多
当需要compact的文件数量达到soft_pending_compaction_byte参数值时会触发write stall,降低写入速度,当达到hard_pending_compaction_byte时会完全停止写入.
TiKV内提供了相关监控用于观察compact的相关活动,可通过TiKV Detail -> RockDB KV/rfat 中相关面板查看。
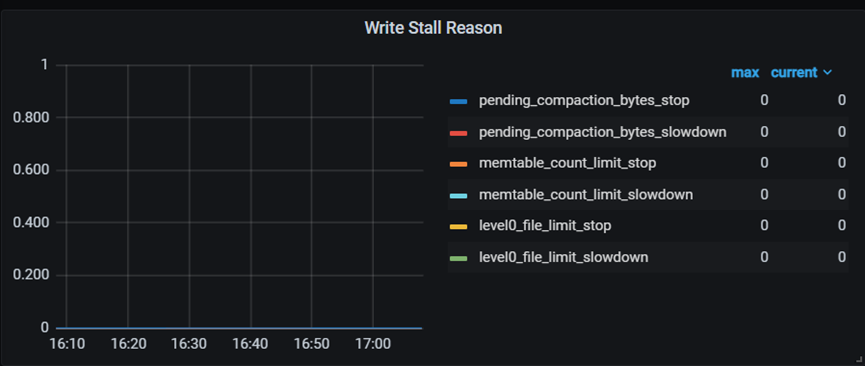
触发write stall的原因可通过Write Stall Reason面板查看。
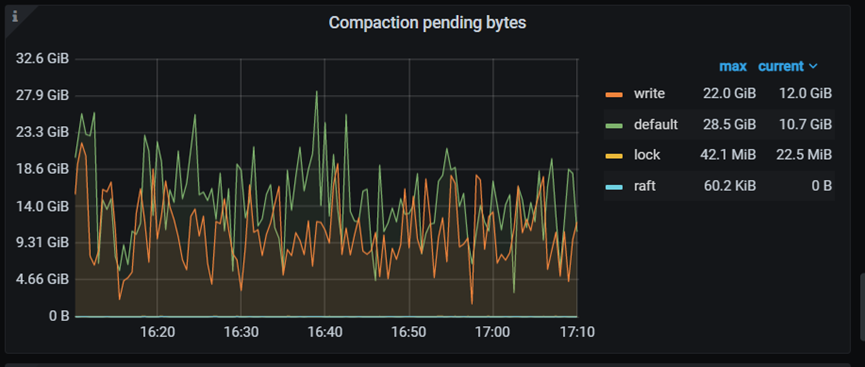
等待compact的文件大小:
Compact的读写速度:
5.2版本开始,tidb优化流控机制,在scheduler层进行流控代替rocksdb的wrtie stall机制,可以避免 write stall 机制卡住 Raftstore 或 Apply 线程导致的次生问题,该功能通过storage.flow-control控制是否开启流量控制机制。开启后,TiKV 会自动关闭 KV DB 的 write stall 机制,还会关闭 RaftDB 中除 memtable 以外的 write stall 机制,除此之外还可以使用memtables-threshold、l0-files-threshold、soft-pending-compaction-bytes-limit、hard-pending-compaction-bytes-limit等参数来进行控制。
14 GC 和 Compaction有哪些关联?
为防止系统中存在大量历史版本数据影响系统性能,TiKV会定期进行GC清理已经过期的历史版本,每隔tidb_gc_run_interval时间就发起一次GC,GC过程主要清理3个步骤,1、resolve lock 清理锁,实际调用使用RockDB的 delete将记录设置为tombstone 。2、truncate/drop table或Index后的sst文件清理,直接使用物理删除sst文件方式。 3、MVCC版本清理,使用RockDB的delete将记录设置为tombstone ,(GC相关原理可参考 :TiDB GC 之原理浅析https://tidb.net/blog/ed740c2c)。
从GC原理可以看出虽然在TiKV层执行的数据清理但在底层RocksDB存储引擎数据是仍然存在的,只是增加了一个被设置了删除标记tombstone记录,对于tombstone记录要等到compact到最底层bottom level时才能真正的删除。
GC属于资源密集型操作,需要较多的IO和CPU消耗,TiDB在5.0版本引入了GC in Compaction Filter功能,在RocksDB compact时进行GC,以降低每次定期GC时处理的数据量,加快GC处理速度,从而减少读操作和降低CPU。CompactionFilter是RocksDB的提供的一个接口,允许用户根据自定义的逻辑去修改或删除 KV,从而实现自定义的垃圾回收。
当RocksDB执行compact时会调用TiKV的CompactionFilter逻辑,获取当前safepoint时间,然后对比WriteCF中的commit_ts,对于safepoint前的记录则不会保留,之后采用异步的方式清理DefaultCF中的对应数据。由于异步清理defaultCF会导致在WriteCF中版本记录已经清理但DefaultCF中的记录却没有清理,产生orphan version,为此TiKV增加了DefaultCF中orphan version记录的清理功能,官方对应GC in Compaction Filter功能也在不断的增强和完善。
GC时CPU监控可通过TiKV Detail -> Thread CPU -> GC Worker CPU面板查看,GC运行的相关监控可通过 TiKV Detail -> GC 相关面板查看。
15 总结
对于TiKV和RockDB都在不断完善compaction机制,以期降低LSM Tree带来的读放大、写放大以及空间放大问题,进一步提升系统性能。同时TiKV中提供了丰富的监控指标用于监控GC 、Compaction等,方便用户掌握相关运行情况、排查write stall等问题原因。
----------------------------------------------------------------
参考资料:
https://github.com/tikv/tikv
https://github.com/facebook/rocksdb/wiki
https://www.jianshu.com/p/88f286142fb7
http://mysql.taobao.org/monthly/2018/10/08/
https://blog.csdn.net/Z_Stand/article/details/107592966
https://kernelmaker.github.io/Rocksdb_Study_5
https://github.com/xieyu/blog/blob/master/src/rocksdb/flush-and-compact.md
https://rocksdb.org/blog/2017/06/26/17-level-based-changes.html
https://github.com/tikv/tikv/pull/8115
https://github.com/facebook/rocksdb/issues/9106