TiFlash 面向编译器的自动向量化加速
作者:朱一帆
目录
SIMD 介绍
SIMD 函数派发方案
面向编译器的优化
SIMD 介绍
SIMD 是重要的重要的程序加速手段。CMU DB 组在 Advanced Database Systems 中有专门的两个章节(vectorization-1, vectorization-2)介绍 SIMD 向量化在数据库中的应用,可见其对现代数据库系统的重要性。本文章简要介绍一些在 TiFlash 中使用编译器进行自动向量化所需要的入门知识。
TiFlash 目前支持的架构是 x86-64 和 Aarch64,操作系统平台有 Linux 和 MacOS。受制于平台 ISA 和操作系统 API,在不同环境中做 SIMD 支持会遇到不同的麻烦。
X86-64
我们在传统上把 x86-64 平台分为 4 个 Level:
x86-64: CMOV, CMPXCHG8B, FPU, FXSR, MMX, FXSR, SCE, SSE, SSE2
x86-64-v2: (close to Nehalem) CMPXCHG16B, LAHF-SAHF, POPCNT, SSE3, SSE4.1, SSE4.2, SSSE3
x86-64-v3: (close to Haswell) AVX, AVX2, BMI1, BMI2, F16C, FMA, LZCNT, MOVBE, XSAVE
x86-64-v4: AVX512F, AVX512BW, AVX512CD, AVX512DQ, AVX512VL
每个层次上有不同的拓展指令集支持。现状是 TiFlash 在 x86-64 上编译的目标是 x86-64-v2,而目前绝大部分家用和服务器 CPU 均已支持 x86-64-v3。由于 Intel 目前面临大小核架构的更新,x86-64-v4 的支持相对混乱,但在服务器方面,比较新的型号均带有不同程度的 AVX512 支持。在 AWS 的支持矩阵中我们可以看到第三代志强可拓展处理器等支持 AVX512 的型号已经被采用于生产环境。
x86-64 上不同 CPU 架构之前相同拓展指令集的开销也是不同的,一般来说,可以在 Intel Intrinsic Guide 上简要查看相关指令在不同微架构上的 CPI 信息。而如果要针对具体的平台优化,则可以阅读平台相关的 Tuning Guides and Performance Analysis Papers ,INTEL® ADVANCED VECTOR EXTENSIONS 以及 Intel® 64 and IA-32 Architectures Software Developer Manuals (Software Optimization Reference Manual 系列)来获得 Intel 官方的建议。
如何选择 SSE,AVX/AVX2,AVX512?其实并不是技术越新,位宽越大,效果就一定越好。如,在 INTEL® ADVANCED VECTOR EXTENSIONS 的 2.8 章我们可以看到,混用传统 SSE 和 AVX 指令集会导致所谓的 SSE-AVX Transition Penalty:
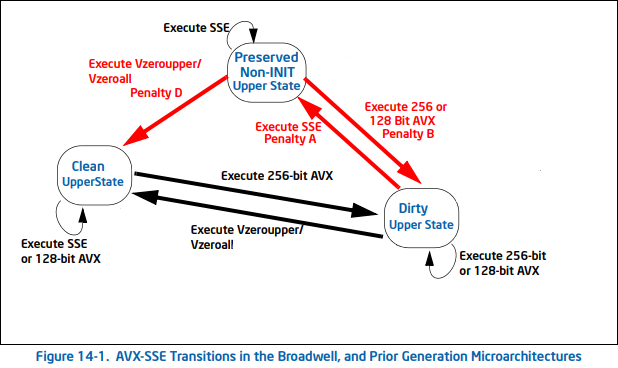
另一方面,AVX2,AVX512 都有相应的 Frequency Scaling 问题。Cloudflare 的文章 On the dangers of Intel's frequency scaling 以及 Gathering Intel on Intel AVX-512 Transitions 对这个问题都有分析。简单而言,AVX-512 在密集计算中可以提高性能,此时 CPU 频率下降,不过向量化本身极大的提升了速度。但是,如果在非密集场景下混用 AVX512 和普通指令,我们可以想象降频给整体性能带来的损失。
在 Intel 平台上,SIMD指令集对应的是 XMM,YMM,ZMM 等寄存器,我们可以用 gdb 的 disassmble 指令来查看向量化的结果:
#!/usr/bin/env bash
args=(-batch -ex "file $1")
while IFS= read -r line;
do
args+=("-ex" "disassemble '$line'")
done < <(nm --demangle $1 | grep $2 | cut -d\ -f3-)
gdb "${args[@]}" | c++filt
# bash ./this-script.sh tiflash xxx
#!/usr/bin/env bash
# LLDB version
args=(--batch -o "file $1")
while IFS= read -r line;
do
args+=("-o" "disassemble -F intel -n '$line'")
done < <(nm --defined-only --demangle $1 | grep $2 | cut -d\ -f3-)
lldb "${args[@]}" | c++filt
# bash ./this-script.sh tiflash xxx
Aarch64
在 Arm 世界里也存在平台向量化指令集支持参差不齐的问题。Arm V8目前已经细化出了 8 个版本:

在 SIMD 方面,Aarch64 主要有两个三个的指令集 ASIMD,SVE,SVE2。ASIMD 已经在广泛应用,事实上, GCC/Clang 会默认打开 ASIMD 支持。 在 Arm V8 中,SVE 一般不在 A Profile 中实现,而是用于 HPC 等的专业 CPU 中。在 Arm V9 中,SVE,SVE2 已经成为标配的拓展指令集。
ASIMD 描述的是定长向量化操作,作用于 64bit 和 128bit 的寄存器,功能上和 SSE 系列接近。SVE 则是使用变长向量,Vendor 可以提供最高到 2048bit 的超宽寄存器。使用 Per-Lane Prediction 的方案,SVE 指令集建立了一种无需知道实际寄存器宽度的编程模型。

在实际应用中,AWS C7g (基于 AWS Graviton3) 已经开始支持 SVE 指令集,最高可达 256bit 宽度。而 ASIMD 则在鲲鹏,AWS Graviton2等 CPU 的实例上都有很好的实现。
在 AARCH64 上,常见的 ASIMD 相关的寄存器是 q0-q15,它们有时也会以 v0-v15 加后缀的形式出现在 ASM 中。SVE 等则使用 z0-z15。

SIMD 函数派发方案
TiFlash 的 CD Pipeline 对于每种OS/Arch组合生成一个统一的二进制文件包进行发布,因此整体编译的目标都是相对通用的架构。而 SIMD 指令集在不同平台具有差异性,因此我们需要一些方案来派发被向量化的函数。以下提供两大类方案,运行时和加载时。整体来说,可以参考以下条件来选择:
如果想支持非 Linux 目标,且已知操作本身用时相对较多,不在乎多一两个 branch,可以使用运行时的派发。在这种情况下,TiFlash 里有提供对应向量化方案的运行时开关,功能更可控 。
如果操作极其大量地被使用,且 branch 可能会影响性能,可以优先考虑加载时派发。TiFlash 在生产环境中基本上使用 Linux,所以可以只为 MacOS 提供默认版本的函数。
运行时派发
这个方案相对简单,在 common/detect_features.h 中,TiFlash 提供了检查具体 CPU 功能的方案,我们可以写一个运行时检查功能,再决定具体实现方案的函数入口。这种方案适用于已知向量化操作耗时比较长,相比可以忽略派发代价的情况。
观察下面这段代码:
__attribute__((target("avx512f"))) void test4096_avx512(bool * __restrict a, const int * __restrict b)
{
for (int i = 0; i < 4096; ++i)
{
a[i] = b[i] > 0;
}
}
__attribute__((target("avx2"))) void test4096_avx2(bool * __restrict a, const int * __restrict b)
{
for (int i = 0; i < 4096; ++i)
{
a[i] = b[i] > 0;
}
}
__attribute__((noinline)) void test4096_generic(bool * __restrict a, const int * __restrict b)
{
for (int i = 0; i < 4096; ++i)
{
a[i] = b[i] > 0;
}
}
void test4096(bool * __restrict a, const int * __restrict b)
{
if (common::cpu_feature_flags.avx512f)
{
return test4096_avx512(a, b);
}
if (common::cpu_feature_flags.avx2)
{
return test4096_avx2(a, b);
}
return test4096_generic(a, b);
}
可以看到,函数入口就是检测功能,呼叫对应平台的实现:
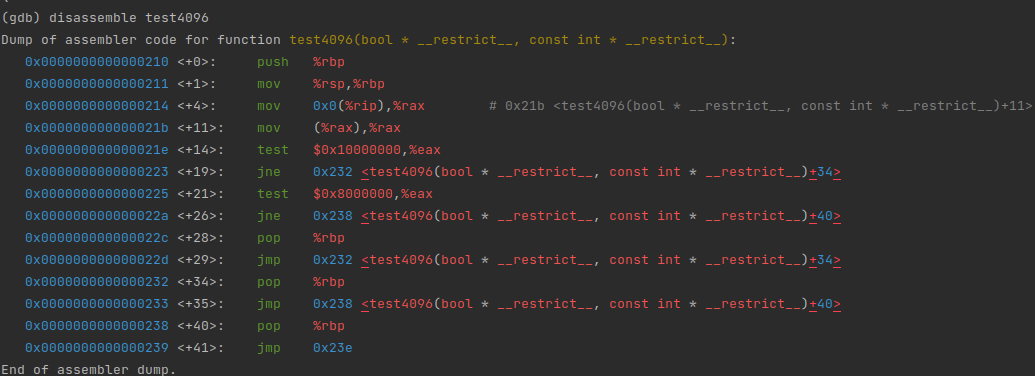
而具体的函数则有相应平台的向量化优化
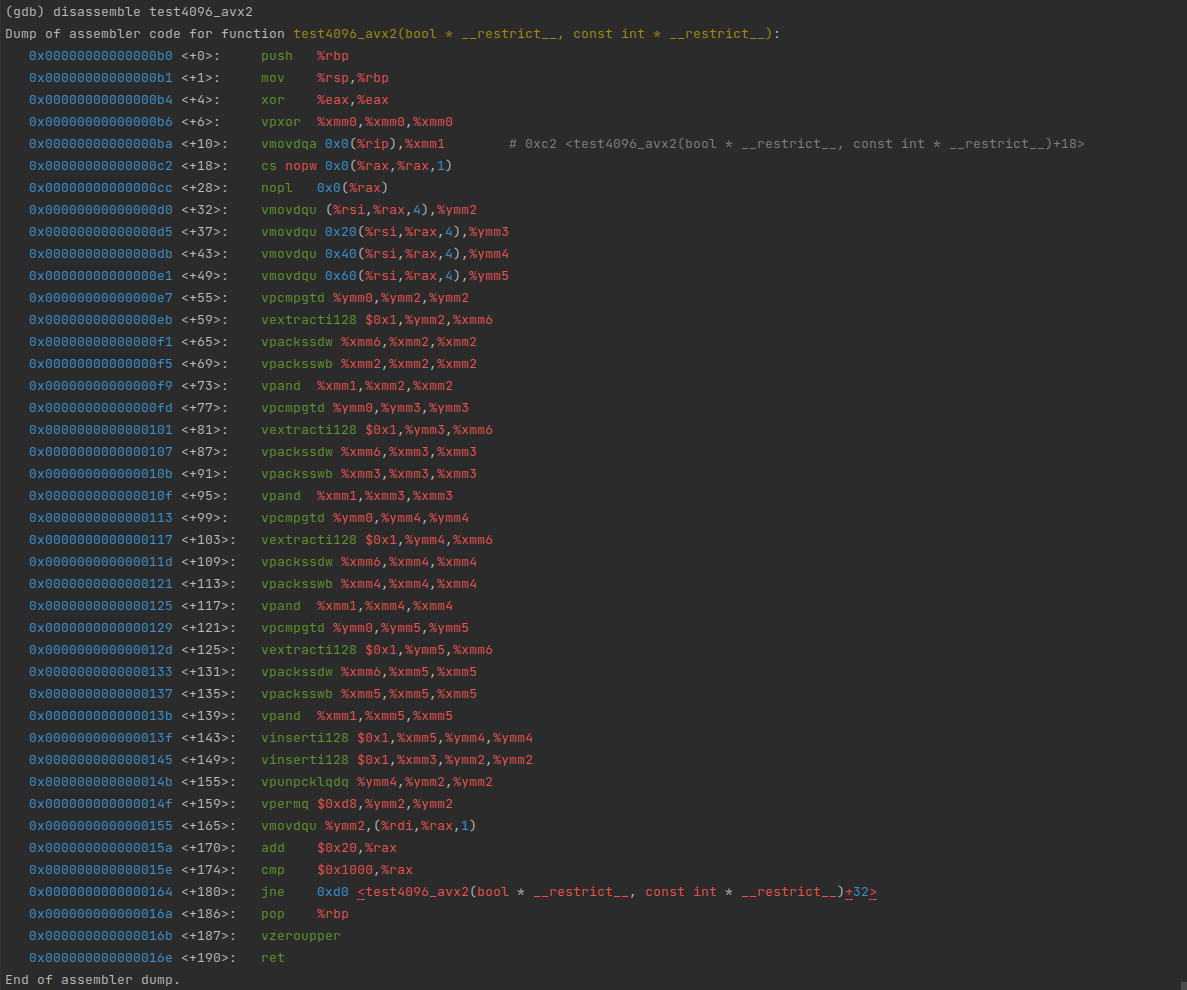
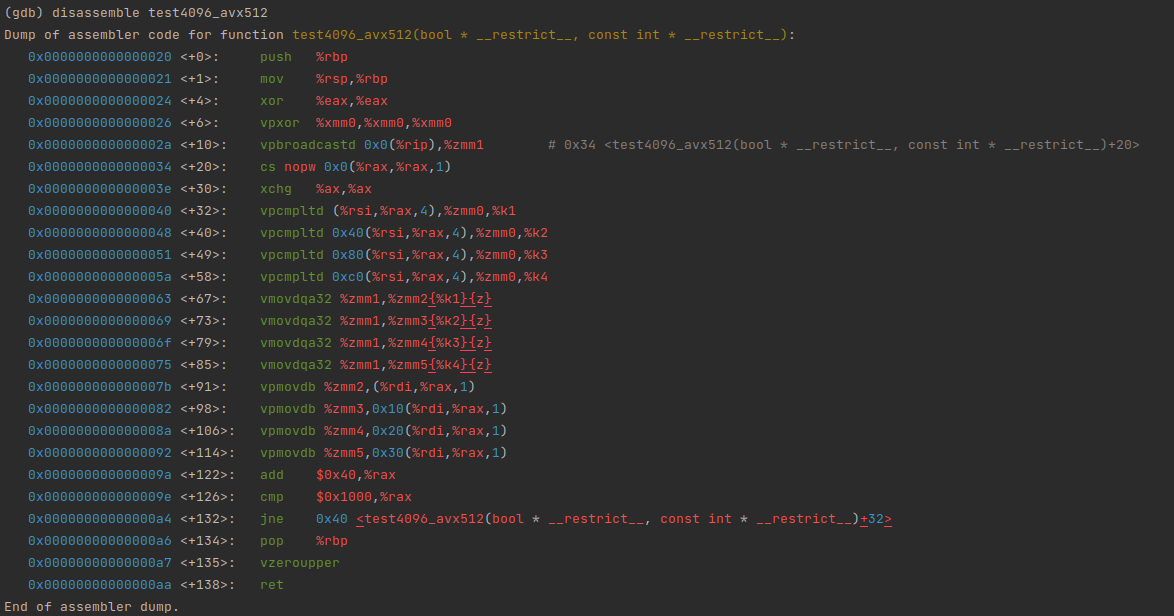
实际上,对于这种同函数体的派发,TiFlash 已经提供了包装好的 macro,以上代码可以写为
#include <Common/TargetSpecific.h>
TIFLASH_DECLARE_MULTITARGET_FUNCTION(
/* return type */ void,
/* function name */ test4096,
/* argument names */ (a, b),
/* argument list */ (bool * __restrict a, const int * __restrict b),
/* body */ {
for (int i = 0; i < 4096; ++i)
{
a[i] = b[i] > 0;
}
})
IFUNC 派发
在 Linux 上观察 Glibc 的符号表:
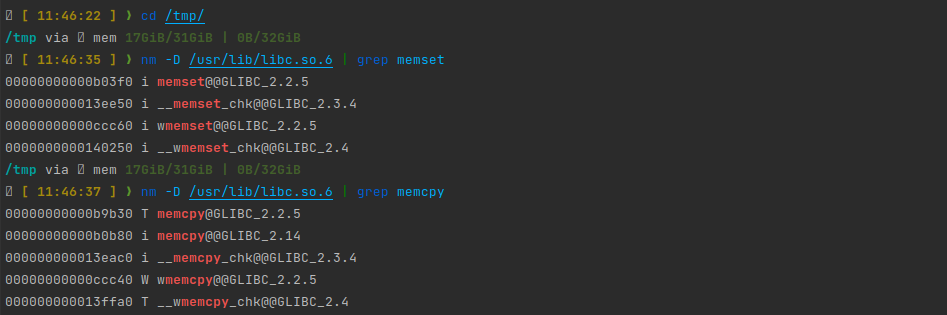
我们可以看到,一些性能关键函数前被标记了i 符号。这表示这些函数是 indirect 函数:即程序可以提供一个函数的多种实现,然后在程序加载链接阶段由 ld 决定目标符号具体链接到哪个实现。Glibc 正是使用这个方案来决定一些关键函数如 memcpy/memcmp/memset 等的实现。
test4096可以改写:
void test4096(bool * __restrict a, const int * __restrict b) __attribute__((ifunc("test4096_resolver")));
extern "C" void * test4096_resolver()
{
if (__builtin_cpu_supports("avx512f"))
return reinterpret_cast<void *>(&test4096_avx512);
if (__builtin_cpu_supports("avx2"))
return reinterpret_cast<void *>(&test4096_avx2);
return reinterpret_cast<void *>(&test4096_generic);
}
这个方案减少了运行时派发的开销,但是也有一定局限性:
仅适用于 GNU/Linux 平台
ifunc 的 resolver 必须在当前 unit 内。如果 resolver 是 c++ 的函数,需要提供 mangle 后的名字。
resolver 执行于进入 C 运行时和 C++ 运行时之前,不能用 TiFlash 的检测功能。在
x86_64平台,可以使用__builtin_cpu_supports; 在aarch64上,可以使用以下方案:#include <sys/auxv.h>
#ifndef HWCAP2_SVE2
#define HWCAP2_SVE2 (1 << 1)
#endif
#ifndef HWCAP_SVE
#define HWCAP_SVE (1 << 22)
#endif
#ifndef AT_HWCAP2
#define AT_HWCAP2 26
#endif
#ifndef AT_HWCAP
#define AT_HWCAP 16
#endif
namespace detail
{
static inline bool sve2_supported()
{
auto hwcaps = getauxval(AT_HWCAP2);
return (hwcaps & HWCAP2_SVE2) != 0;
}
static inline bool sve_supported()
{
auto hwcaps = getauxval(AT_HWCAP);
return (hwcaps & HWCAP_SVE) != 0;
}
} // namespace detail另外一个有趣的例子是,如果你需要在 resolver 中读取函数变量,你可能需要手动初始化 environ 指针:
extern char** environ;
extern char **_dl_argv;
char** get_environ() {
int argc = *(int*)(_dl_argv - 1);
char **my_environ = (char**)(_dl_argv + argc + 1);
return my_environ;
}
typeof(f1) * resolve_f() {
environ = get_environ();
const char *var = getenv("TOTO");
if (var && strcmp(var, "ok") == 0) {
return f2;
}
return f1;
}
int f() __attribute__((ifunc("resolve_f")));
Function Multiversioning 派发
在 x86-64 上,Clang/GCC 实际上提供了更便捷的 IFUNC 实现方案:
#include <iostream>
__attribute__((target("avx512f"))) void test4096(bool * __restrict a, const int * __restrict b)
{
std::cout << "using avx512" << std::endl;
for (int i = 0; i < 4096; ++i)
{
a[i] = b[i] > 0;
}
}
__attribute__((target("avx2"))) void test4096(bool * __restrict a, const int * __restrict b)
{
std::cout << "using avx2" << std::endl;
for (int i = 0; i < 4096; ++i)
{
a[i] = b[i] > 0;
}
}
__attribute__((target("default"))) void test4096(bool * __restrict a, const int * __restrict b)
{
std::cout << "using default" << std::endl;
for (int i = 0; i < 4096; ++i)
{
a[i] = b[i] > 0;
}
}
int main() {
bool results[4096];
int data[4096];
for (auto & i : data) {
std::cin >> i;
}
test4096(results, data);
for (const auto & i : results) {
std::cout << i << std::endl;
}
}
这里,我们不用区分函数名和提供 resolver,而是直接标记不同的 target,编译器会自动生成 ifunc 的实现。
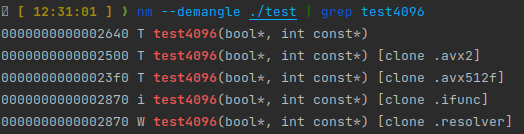
Macro 整合
可以使用以下代码整合 x86-64 和 aarch64 上的基于 IFUNC 的方案:
#ifdef __linux__
#include <sys/auxv.h>
#ifndef HWCAP2_SVE2
#define HWCAP2_SVE2 (1 << 1)
#endif
#ifndef HWCAP_SVE
#define HWCAP_SVE (1 << 22)
#endif
#ifndef AT_HWCAP2
#define AT_HWCAP2 26
#endif
#ifndef AT_HWCAP
#define AT_HWCAP 16
#endif
namespace detail
{
static inline bool sve2_supported()
{
auto hwcaps = getauxval(AT_HWCAP2);
return (hwcaps & HWCAP2_SVE2) != 0;
}
static inline bool sve_supported()
{
auto hwcaps = getauxval(AT_HWCAP);
return (hwcaps & HWCAP_SVE) != 0;
}
} // namespace detail
#endif
#define TMV_STRINGIFY_IMPL(X) #X
#define TMV_STRINGIFY(X) TMV_STRINGIFY_IMPL(X)
#define TIFLASH_MULTIVERSIONED_VECTORIZATION_X86_64(RETURN, NAME, ARG_LIST, ARG_NAMES, BODY) \
struct NAME##TiFlashMultiVersion \
{ \
__attribute__((always_inline)) static inline RETURN inlined_implementation ARG_LIST BODY; \
\
__attribute__((target("default"))) static RETURN dispatched_implementation ARG_LIST \
{ \
return inlined_implementation ARG_NAMES; \
}; \
\
__attribute__((target("avx"))) static RETURN dispatched_implementation ARG_LIST \
{ \
return inlined_implementation ARG_NAMES; \
}; \
\
__attribute__((target("avx2"))) static RETURN dispatched_implementation ARG_LIST \
{ \
return inlined_implementation ARG_NAMES; \
}; \
\
__attribute__((target("avx512f,avx512vl,avx512bw,avx512cd"))) static RETURN dispatched_implementation ARG_LIST \
{ \
return inlined_implementation ARG_NAMES; \
}; \
\
__attribute__((always_inline)) static inline RETURN invoke ARG_LIST \
{ \
return dispatched_implementation ARG_NAMES; \
}; \
};
#define TIFLASH_MULTIVERSIONED_VECTORIZATION_AARCH64(RETURN, NAME, ARG_LIST, ARG_NAMES, BODY) \
struct NAME##TiFlashMultiVersion \
{ \
__attribute__((always_inline)) static inline RETURN inlined_implementation ARG_LIST BODY; \
\
static RETURN generic_implementation ARG_LIST \
{ \
return inlined_implementation ARG_NAMES; \
}; \
\
__attribute__((target("sve"))) static RETURN sve_implementation ARG_LIST \
{ \
return inlined_implementation ARG_NAMES; \
}; \
\
__attribute__((target("sve2"))) static RETURN sve2_implementation ARG_LIST \
{ \
return inlined_implementation ARG_NAMES; \
}; \
\
static RETURN dispatched_implementation ARG_LIST \
__attribute__((ifunc(TMV_STRINGIFY(__tiflash_mvec_##NAME##_resolver)))); \
\
__attribute__((always_inline)) static inline RETURN invoke ARG_LIST \
{ \
return dispatched_implementation ARG_NAMES; \
}; \
}; \
extern "C" void * __tiflash_mvec_##NAME##_resolver() \
{ \
if (::detail::sve_supported()) \
{ \
return reinterpret_cast<void *>(&NAME##TiFlashMultiVersion::sve_implementation); \
} \
if (::detail::sve2_supported()) \
{ \
return reinterpret_cast<void *>(&NAME##TiFlashMultiVersion::sve2_implementation); \
} \
return reinterpret_cast<void *>(&NAME##TiFlashMultiVersion::generic_implementation); \
}
#if defined(__linux__) && defined(__aarch64__)
#define TIFLASH_MULTIVERSIONED_VECTORIZATION TIFLASH_MULTIVERSIONED_VECTORIZATION_AARCH64
#elif defined(__linux__) && defined(__x86_64__)
#define TIFLASH_MULTIVERSIONED_VECTORIZATION TIFLASH_MULTIVERSIONED_VECTORIZATION_X86_64
#else
#define TIFLASH_MULTIVERSIONED_VECTORIZATION(RETURN, NAME, ARG_LIST, ARG_NAMES, BODY) \
struct NAME##TiFlashMultiVersion \
{ \
__attribute__((always_inline)) static inline RETURN invoke ARG_LIST BODY; \
};
#endif
TIFLASH_MULTIVERSIONED_VECTORIZATION(
int,
sum,
(const int * __restrict a, int size),
(a, size),
{
int sum = 0;
for (int i = 0; i < size; ++i) {
sum += a[i];
}
return sum;
}
)
面向编译器的优化
LLVM 提供了一个很好的自动向量化指南: Auto-Vectorization in LLVM - LLVM 15.0.0git documentation
可以参考其中的章节了解哪些常见模式可以用于向量化。简单来说,我们可以思考循环的场景:能否简化不必要的控制流,能否减少不透明的函数呼叫等等。除此之外,还可以考虑,对于一些简单的函数定义,如果它会被大量连续呼叫,我们能否将函数定义在 header 中,让编译器看到并内联这些函数,进而提升向量化的空间。
高德纳说过,premature optimization is the root of all evil(过早优化是万恶之源)。我们没有必要为了向量化就把一些非性能关键部分的循环重写成向量化友好的形式。结合 profiler 来决定进一步优化那些函数是一个比较好的选择。
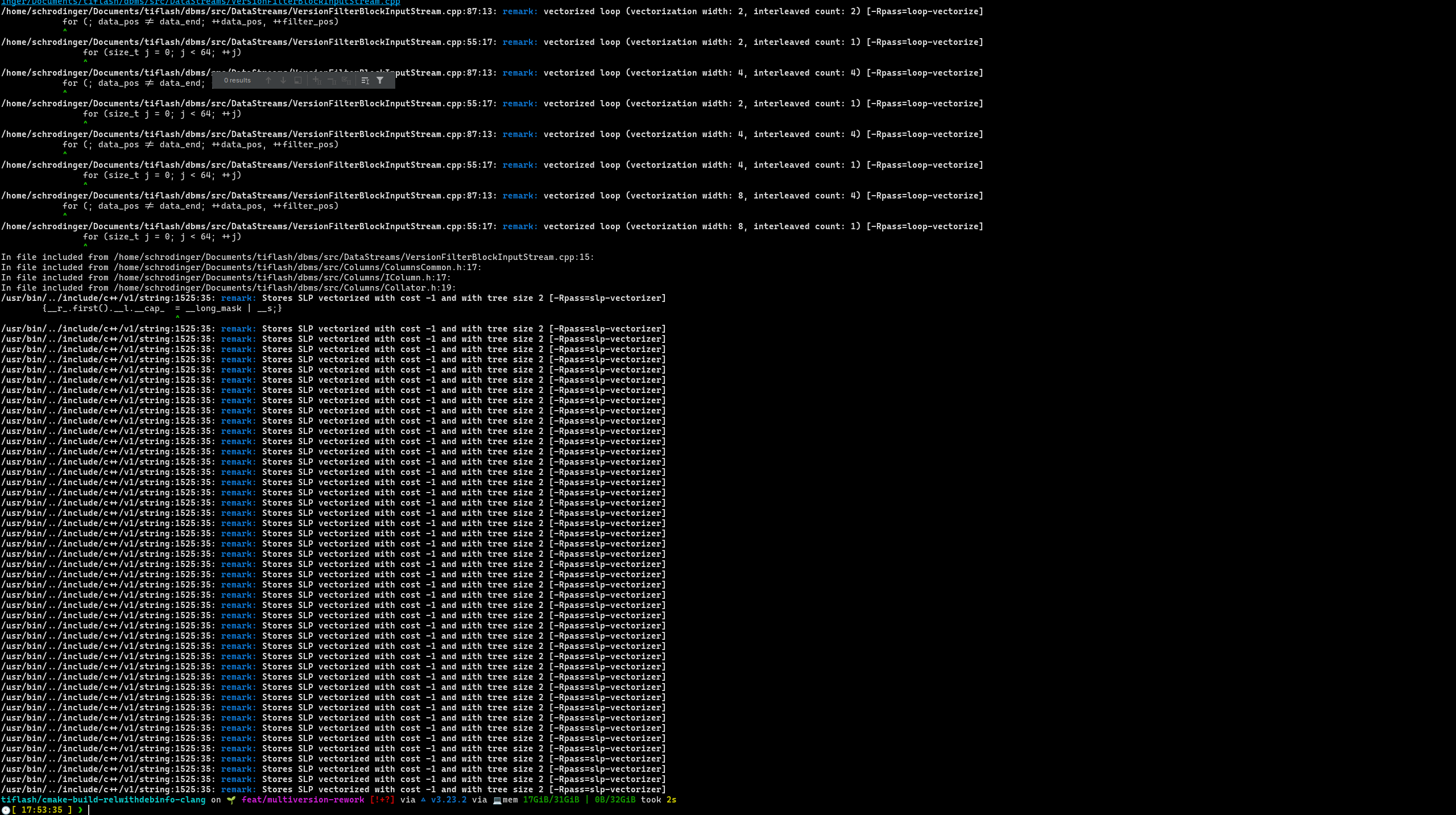
检查向量化条件
我们使用以下参数检查向量化过程:
-Rpass-missed='.*vectorize.*'检查编译器为什么没有成功向量化-Rpass='.*vectorize.*'检查编译器进行了那些向量化
具体地,在 TiFlash,我们先提取某个 object file 的编译指令
cat compile_commands.json | grep "/VersionFilterBlockInputStream.cpp"
然后,在编译指令前添加 -Rpass-missed='.*vectorize.*'或者-Rpass='.*vectorize.*'来查看相关信息。

循环展开 Pragma
以下 pragma 可以用来控制循环展开策略,辅助向量化
void test1(int * a, int *b, int *c) {
#pragma clang loop unroll(full)
for(int i = 0; i < 1024; ++i) {
c[i] = a[i] + b[i];
}
}
void test2(int * a, int *b, int *c) {
#pragma clang loop unroll(enable)
for(int i = 0; i < 1024; ++i) {
c[i] = a[i] + b[i];
}
}
void test3(int * a, int *b, int *c) {
#pragma clang loop unroll(disable)
for(int i = 0; i < 1024; ++i) {
c[i] = a[i] + b[i];
}
}
void test4(int * a, int *b, int *c) {
#pragma clang loop unroll_count(2)
for(int i = 0; i < 1024; ++i) {
c[i] = a[i] + b[i];
}
}
向量化 Pragma
以下 pragma 可以建议 clang 进行向量化。
static constexpr int N = 4096;
int A[N];
int B[N];
struct H {
double a[4];
H operator*(const H& that) {
return {
a[0] * that.a[0],
a[1] * that.a[1],
a[2] * that.a[2],
a[3] * that.a[3],
};
}
};
H C[N];
H D[N];
H E[N];
void test1() {
#pragma clang loop vectorize(enable)
for (int i=0; i < N; i++) {
C[i] = D[i] * E[i];
}
}
void test2() {
for (int i=0; i < N; i++) {
C[i] = D[i] * E[i];
}
}
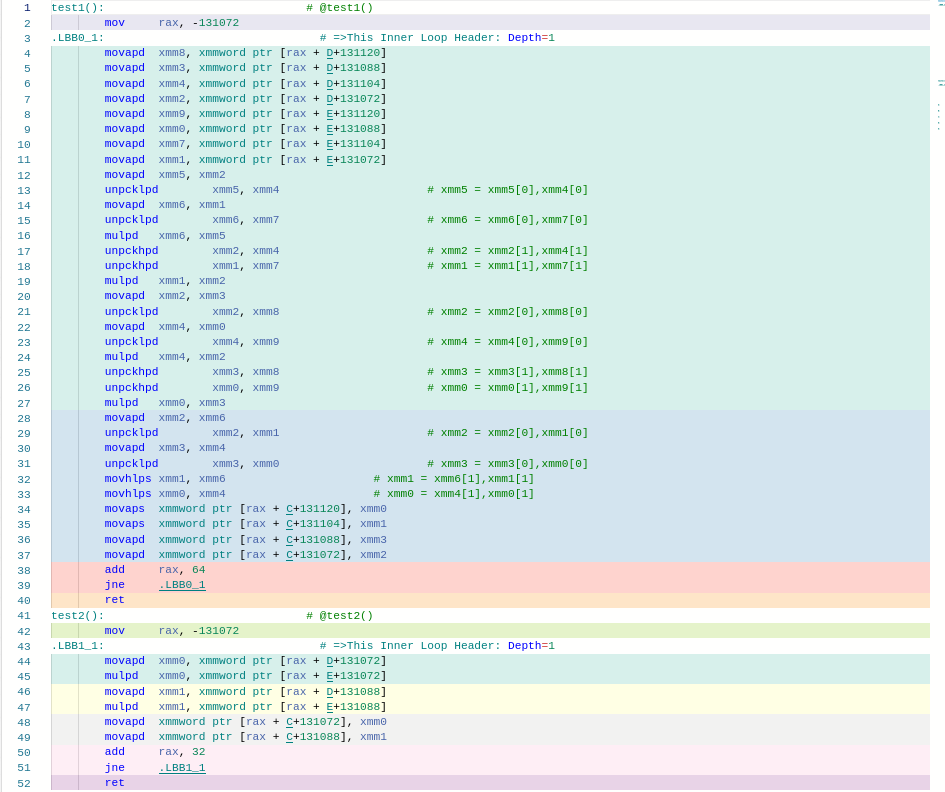
事实上,在 Aarch64 上,TiFlash 中 getDelta 默认就没有向量化,而使用 hint 后则可以。
这些 pragma 如果想在 macro 内部使用,可以改为 _Pragma("clang loop vectorize(enable)") 的形式。
循环拆分
复用上面的例子
void x() {
#pragma clang loop vectorize(enable)
for (int i=0; i < N; i++) {
A[i + 1] = A[i] + B[i];
C[i] = D[i] * E[i];
}
}
void y() {
for (int i=0; i < N; i++) {
A[i + 1] = A[i] + B[i];
}
#pragma clang loop vectorize(enable)
for (int i=0; i < N; i++) {
C[i] = D[i] * E[i];
}
}
其中 x 函数没有被向量化,因为 A 中存在数据依赖。y 中拆分两个loop后,后一个 loop 则可以进行向量化。在实际情况下,如果 C[i] = D[i] * E[i] 的标量操作会相对占用时间,这样做循环拆分是比较有意义的。
理论上
#pragma clang loop distribution(enable)
可以自动处理相应情况,但是这里即使使用这个 pragma,clang 仍然会相对保守。
控制向量化策略
调整单位向量大小
void test(char *x, char *y, char * z) {
#pragma clang loop vectorize_width(8)
for (int i=0; i < 4096; i++) {
x[i] = y[i] * z[i];
}
}
比如在 Aarch64 上,vectorize_width(1) 意味着没有向量化,vectorize_width(8) 意味着用 64bit 寄存器,vectorize_width(16) 意味着用 128bit 寄存器。
除此之外,还可以用 vectorize_width(fixed) , vectorize_width(scalable) 调整对定长和变长向量的倾向。
调整向量化批次大小
可以用 interleave_count(4) 向编译器建议向量化时展开的循环批次。在一定范围内提高批次大小可以促进处理器利用超标量和乱序执行进行加速。
void test(char *x, char *y, char * z) {
#pragma clang loop vectorize_width(8) interleave_count(4)
for (int i=0; i < 4096; i++) {
x[i] = y[i] * z[i];
}
}
提取定长循环单元
以下函数用来确认数据库列存中第一个可见列:
const uint64_t* filterRow(
const uint64_t* data,
size_t length,
uint64_t current_version) {
for(size_t i = 0; i < length; ++i) {
if (data[i] > current_version) {
return data + i;
}
}
return nullptr;
}
它不能被向量化,因为循环内部有存在向外跳转的控制流。
这种情况下,可以手动提取出一段循环来帮助编译器做自动向量化:
const uint64_t* filterRow(
const uint64_t* data,
size_t length,
uint64_t current_version) {
size_t i = 0;
for(; i + 64 < length; i += 64) {
uint64_t mask = 0;
#pragma clang loop vectorize(enable)
for (size_t j = 0; j < 64; ++j) {
mask |= data[i + j] > current_version ? (1ull << j) : 0;
}
if (mask) {
return data + i + __builtin_ctzll(mask);
}
}
for(; i < length; ++i) {
if (data[i] > current_version) {
return data + i;
}
}
return nullptr;
}
(__builtin_ctzll 是用来计算整数末尾0的个数的编译器内建函数,一般可以高效地翻译成一条指令)