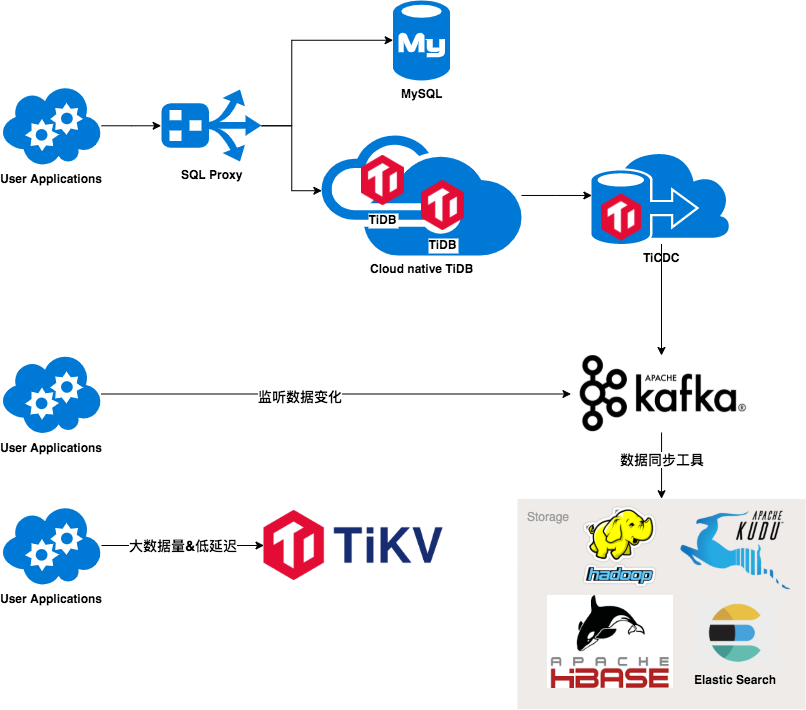
车好多的数据库选型经验与 TiDB 实践
作者:车好多 TiDB 虚拟团队成员:葛凯文,韩建生,汪涉洋,TUG Ambassdor
文章首发于 2020 年 11 月
一、背景
车好多集团系国内领军的汽车消费服务一站式平台,旗下拥有瓜子二手车、毛豆新车、车好多车后三大核心业务。车好多集团关注 TiDB 始于 2018 年初,像大多数公司一样,公司发展初期为了快速适配业务开发,大部分数据都存储在 MySQL 中。但随着业务快速发展,存量数据越来越多,我们在 MySQL 面临着如下痛点:
1、业务拆分复杂
公司业务发展快,单实例的 QPS 和数据存储会超出预期,这时候需要对业务线实例进行拆分。每次业务线拆分需要从数据产生端 (APP) 到数据流转端 (CDC) 最后到数据仓库 (DW) 一起配合调整;如果涉及到多方同时使用相同库表,还需要多个应用的负责人协调; 同时一些脚本类程序可能在迁移时被忽略,部分业务数据会受到影响。每次业务线拆分的周期大概在 2-4 周,耗费人力。
2、分库分表侵入业务
业务发展到一定程度之后,一些数据表的数据量超过千万级别,常规做法是分库分表。这里有几个可能遇到的问题:
- 分布式事务不好处理;
- 二级索引无法创建:
- 分库分表的设计是否支持二次扩容;
- 跨库 join 无法操作;
- 结果集的排序合并难度大。
3、大表结构修改困难
我们公司的业务模式变化快,为了快速响应业务,表结构经常调整。在对一些数据在百万级别以上的大表做 DDL 的时候,会借助第三方工具,如 pt-osc 。修改过程中需要先复制一份临时表,这种方式修改的时间较长,对存储空间、IO、业务有一定的影响。
二、数据库选型
面对以上痛点,我们开始考虑对数据库的架构进行升级改造,我们根据业务方的诉求,将一些常见数据库技术方案,做了一些对比:
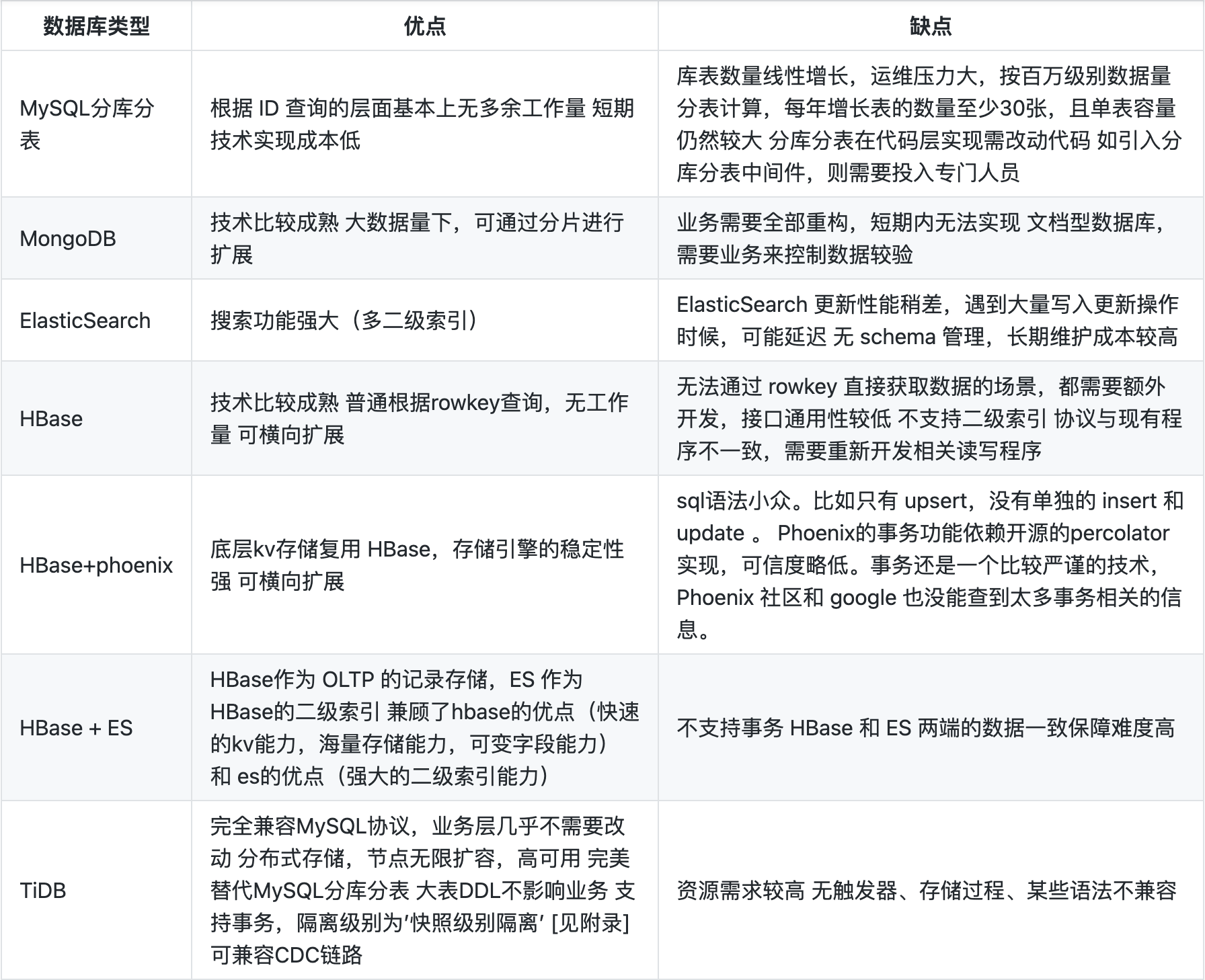
TiDB具有水平弹性扩展,高度兼容 MySQL,在线 DDL,一致性的分布式事务等特性,符合车好多部分数据量大,业务变更频繁,数据保存周期长等场景。我们经过 TiDB 的内部测试后,确认可以满足现有业务需求。我们最终选择了 TiDB 做为这类需求的数据存储。
三、初次探索
1、业务场景
综合 TiDB 的特性和车好多集团的业务场景,我们比较适合引入 TiDB 的场景有:工单分配/流转、电话销售系统、业务中台-账务系统等业务。首先这些业务积累的数据量比较大,在此基础上一部分业务会有频繁增加字段的需求,也有一部分业务会使用到事务,这些场景都非常适用于 TiDB。
2、面临问题
与目标业务方进行了一轮沟通之后,业务方给我们介绍了一些数据的现状和业务上的需求:
- 上线之前存量数据接近 3 亿条,每日新增 170 万条,单月约 5000 万增量。MySQL 中热数据即使只存储最新 2 个月,也面临单表数据破亿的场景;
- 由于车好多集团的业务特殊性,车的周转周期比较长,一些冷数据可能会转变为热数据,归档逻辑与业务需求强绑定,一些所谓的“冷数据”可能会有更新操作;
- 这些数据针对线上用户提供服务,对数据库的实时性读写性能要求较高;
- 同一份数据有多方在使用,针对不同需求查询重点不同,业务查询条件复杂;
- 当数据发生变更时,有相应的业务逻辑处理,需要配置 CDC 数据链路监控数据变化。
3、接入要求
由于 TiDB 的资源要求较高,我们对接入的业务提出了以下要求:
- 存量数据在千万以上,未来 MySQL 的单机存储和性能会成为瓶颈;
- 业务涉及到事务 / 分库分表 / 经常在线增加字段等特殊场景;
- 数据价值较高,提供针对用户的在线服务。
4、接入过程
面对一个新的数据库,大部分核心业务还是担心数据库的稳定性和数据的可靠性,不敢直接尝试。我们优先选择一些数据量比较大并且实时性需求相对较低的场景进行试点,但是业务方仍然担心服务的稳定性和性能等诸多问题。我们多次与业务方沟通,制定和实施了分段落地的计划:
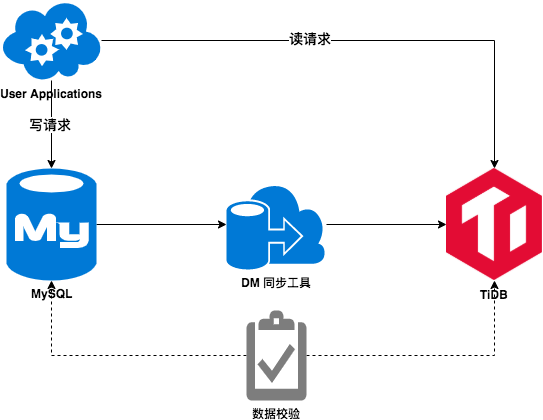
- 第一步,将 TiDB 作为 MySQL 的从库使用,通过 DM 工具同步数据。业务方使用这套 TiDB 集群作为从库,验证数据的准确性 / 服务的稳定性 / 查询的性能等是否符合业务需求,测试正常后灰度小比例的线上流量到该集群上进行查询,确认数据正常后逐步放大灰度的比例直至全流量。这一步充分地验证了 TiDB 的数据同步和数据查询,业务方对 TiDB 有了初步的认知,也逐渐积累了对 TiDB 和维护人员的信任。
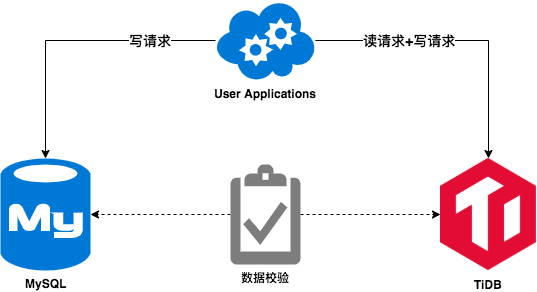
- 第二步,业务方改造程序,对 MySQL 和 TiDB 进行双写,断开 DM 同步。业务方将 TiDB 作为主库直接读写,但仍然保留了 MySQL 中的数据写入,将 MySQL 作为 TiDB 发生异常之后的降级方案。这个阶段持续了 2 个季度左右。在这期间读写 TiDB 的程序运行正常,每天的数据校验保持一致。
- 第三步,下线双写,仅保留直接操作 TiDB 的部分。通过第一步和第二步的验证和积累的信任,TiDB 正式作为独立的数据库投入到生产环境使用.

新车业务接入 TiDB 之后,业务上将原先只支持近期三个月的查询扩展到支持全量查询,这部分数据对用户行为精细化管理带来了一定的帮助。随着业务发展,存量数据从千万级别逐步上升到亿级别,到现在将近十亿,在 1000 QPS 下查询的 99.9th 延迟低于 128 毫秒,用户体验良好。经过了整个接入过程后,新车计划将存在数据库瓶颈的业务逐步迁移到 TiDB 中来。经过一年的发展,目前车好多的二手车收售车管理、台账、支付网关、用户社群等业务逐步 尝试 TiDB,并且在试用之后慢慢从 MySQL 中迁移更多的业务模块到 TiDB 中。
5、遇到的问题
在推进 TiDB 的过程中,我们也遇到了各种问题,除了一些常见的慢 SQL、热点读写、DM 同步数据异常等问题外,我们在车好多的业务背景下,遇到了一些相对特殊的问题:
版本的选择
TiDB 是一项比较新的技术,社区的版本在不断的迭代更新,有很多 bugfix 和新特性在持续集成到 TiDB 中。我们从开始调研到现在,经历了 2.X 到 4.0.X 的多个版本。我们选择了一些比较关心的内容进行跟进,如:Lightning 导入数据 bug 修复、悲观锁、TiFlash、TiUP 管理工具、TiCDC 等等。有一次我们从 2.1.x 的版本升级到 3.0.x 版本,未注意到 sql mode 变更,恰好业务上正好有 SQL 被 ‘ONLY_FULL_GROUP_BY’ 规则影响,紧急修改 SQL 后重新上线。我们增量的业务选择版本的时候,通常会选择一些已经平稳运行一段时间的版本,上线之后,如果没有严重的 bug 或者急需的特性,通常不再进行升级,以保障业务不因为数据库的升级受到影响。
SQL 执行计划 & SQL binding
使用 TiDB 一段时间后,某个业务线单表存量数据数据已经超过 5亿,QPS 也超过了 200。 某天业务方反馈,线上系统发生大量查询超时,结果无返回,TiDB-admin 协助排查问题。观察监控数据,发现 CPU 被打满,IO 上升明显。继续观察慢 SQL 日志,发现在 analyze 收集统计信息的末尾阶段,有一类 SQL 索引的选择发生了改变,每次扫描的 key 从正常索引下的百级别到异常索引下的百万到千万的级别。为了快速恢复业务,结合 TiDB 承载的业务的特性,将影响优化器选择的未使用到的索引删除,同时将自动 analyze 操作设置为业务低谷时间段执行。我们以这个案例咨询了 PingCAP 官方,因为 TiDB 使用的是基于成本的优化器(CBO),在统计信息变更的时候,有可能选择与之前不一致的索引,建议通过 SQL binding 解决此类问题。不久时间后,另一条业务线的 SQLl 因为类似问题,使用了 SQL binding 进行了绑定,在程序使用到 prepare statement 的时候遇到了另一个 bug,上报社区后已经加入到修复计划中。
资源隔离
随着 TiDB 技术在车好多集团的推进,和第一批吃了螃蟹的业务方的推荐,越来越多的业务线希望尝试 TiDB。受机房设备采购周期的限制,我们很难短期内凑出多套独立的 TiDB 集群,服务突然上升的需求量。
结合这些新增需求的业务特性:
- 大部分是增量比较高,但是没有存量数据的业务;
- 前期对资源的需求并不是非常高。
于是我们 TiDB-admin 开始调研在同一组机器中混和部署多套集群,并且进行进程之间的资源隔离。
- TiDB 分为多个组件,PD 对资源的需求不高,暂时忽略;
- TiKV 可以通过软件层配置最大的 CPU 和内存,IO 的隔离我们选择在同一台机器部署多块 SSD 进行物理隔离,也比较好控制;
- TiDB 虽然可以通过软件层配置最大的 CPU 和内存,但是无法阻止瞬时的内存暴增,调研后发现在通过 TiUP 部署的时候,可以设置 systemd 的参数 memory_limit,通过系统的 cgroup 限制最大使用内存,这也催生了我们通过 K8s+Docker 来全面控制资源的想法。
我们在混和部署之后,提供给了业务方进行验证,确认可以隔离某一方的异常 SQL 对冲物理机下其他 TiDB 集群的影响,新业务逐步用上了 TiDB。
四、TiDB 未来工作
- 尝试 TiDB 在车好多云上的实践:随着云原生技术的不断发展,TiDB 作为一款为云原生设计的分布式数据库,可以通过 TiDB Operator 在云上工具化部署,自动化处理资源分配,提升 TiDB 的资源利用率,同时也降低了 TiDB 的维护成本。
- 探索 TiKV 覆盖到的场景:广告投放的业务对服务的访问延迟时间非常敏感,如果延迟过高,用户的体检会大大下降,伴随车好多五年来的数据积累,我们用作广告投放所积累的数据量也非常大,因此我们将 TiKV 作为可持久化的、低延迟的 KV 服务,提供给广告投放的业务来使用,技术方案已经经过了线上流量的考验,由于汽车的交易周期较长,该项目仍然处于业务初期阶段。在未来我们将探索更多的 TiKV 的使用场景,提供可持久化的、低延迟的 KV 服务。
- CDC 的应用: 车好多的数据流服务在 MySQL 数据库上是基于 Binlog 进行建设的,切换到 TiDB 后,使用过 Pump+drainer 的方式同步 Binlog。 在 TiDB 4.0 版本后加入了 CDC 服务,可以更方便地部署和集成多数据格式的输出,未来我们会逐步接入 CDC 的数据到现有系统中。
- 接入车好多数据库运维平台:伴随车好多的成长,我们的 DBA 团队开发并维护了一套管理 MySQL 的系统,管理员和开发的同事都可以很方便地在此系统上完成日常工作,为了维护入口的统一,TiDB 将逐步接入该系统,便于 TiDB 运维的自动化。
- 提供更方便的接入方式:现有的几条业务线的接入,大多是先通过 DM 同步数据,然后与业务方一起配合做一次迁移。我们希望未来可以更方便地服务业务方,通过一个 SQL proxy 的代理层辅助,业务方只需要连接到 proxy 层,后端是 MySQL 或者 TiDB 对于业务方不需要关心,真正做到对业务 0 侵入。