诊断 SOP | GC 常见问题排查
GC 机制
详见官网文档 GC 机制简介
诊断工具
- 重要监控指标
GC Tasks & GC Tasks duration:gc_worker 处理的 GC 任务的个数和执行 GC 任务时所花费的时间。
total-gc: 总的 GC 任务数。每个 GC 任务会清理一个 region 待 GC 的 keys(compaction filter 关闭时有效)。
skipped-gc/failed-gc: 跳过的 GC 任务和失败的 GC 任务(compaction filter 关闭时有效)。GC 时根据 rocksdb 记录的元信息判断,当没有很多版本要清理的 region 可以跳过。
total-unsfe_destroy_range: Delete Ranges 阶段调用的 UnsafeDestroyRange 任务数。
total-orphan_versions / total-gc_keys: compaction filter 发起的 GC 任务,用于处理 compaction filter 不能直接清理的数据。
Auto GC Progress:各个 TiKV Do GC 阶段的进度(compaction filter 关闭时有效)。
- 每一轮 GC TiKV scan 数据时进度会从 0 涨到 100%,这个指标只是粗略计算,可能比 TiDB 的 GC 周期要慢一些,如果 TiKV GC 不活跃则为进度 0。
Auto GC SafePoint:各个 TiKV Do GC 阶段使用的 safepoint,该 safepoint 由每台 TiKV 定期从 PD 获取。
GC Speed:GC 时每秒删除的 key 的数量。无论是否开启 compaction filter 都有效。
GC scan write details / GC scan default details:GC scan 时 RocksDB iterators 统计的操作事件,分为 write CF 和 default CF,与 Coprocessor - Total Ops Details by CF 指标类似。
GC in Compaction Filter:write CF 的 compaction filter 中已过滤版本的数量。
- filtered: compaction 时过滤掉的所有 keys 数量,类型包括 put、delete、rollback、lock 等 。
- rollback/lock: compaction 时过滤的 keys 当中包含的 rollback 和 lock keys 的数量,rollback/lock keys 只是在事务回滚和 select for update 时产生的特殊 key,不代表实际数据。
- 系统表 mysql.tidb
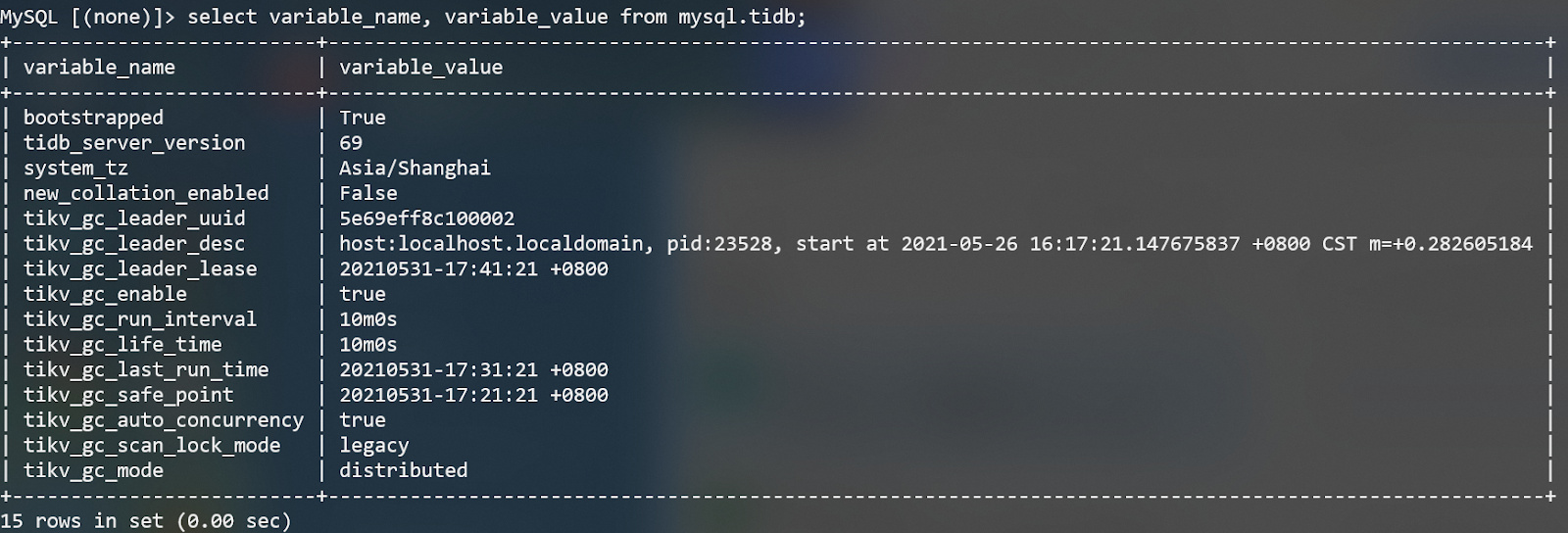
以 tikv_gc 开头的变量都与 GC 相关,其中 tikv_gc_leader_uuid/tikv_gc_leader_desc/tikv_gc_leader_lease 用于记录 GC leader 的状态,tikv_gc_safe_point 和 tikv_gc_last_run_time 在每轮 GC 开始前会被自动更新,其他几个变量则是可配置的,详见 GC 配置。
注意:从 5.0 开始建议通过 set 变量的方式来设置 tidb_gc_life_time 等参数,而不是直接修改 update mysql.tidb,避免修改成错误格式的参数导致 GC 不正常。
- GC leader 日志
通过 mysql.tidb 表的 tikv_gc_leader_desc 字段找到 leader 所在的 TiDB 节点,然后过滤 gc_worker 关键字的日志。
grep "gc_worker" tidb.log | less
- CLI 命令
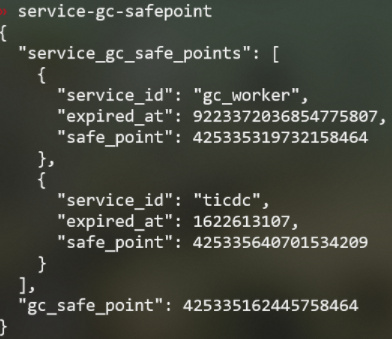
pd-ctl service-gc-safepoint 查询所有 service 的 gc safepoint。
- "service_gc_safe_points": gc_worker/ticdc/br/dumpling 等各 service 记录的 safe point。
- "gc_safe_point": 用于通知 TiKV 进行 Do GC 的 safe point,该 safe point 不保证在此时间之后的数据可以安全读取。
如何判断 GC 所在阶段
GC 分为 Resolve Locks, Delete Ranges 和 Do GC 三个阶段。
Resolve Locks 阶段:在 TiKV 一侧会产生大量的 scan_lock 请求,可以在 gRPC 相关的 metrics 中观察到。scan_lock 请求会对全部的 Region 调用。
Delete Ranges 阶段:会往 TiKV 发送少量的 unsafe_destroy_range 请求,也可能没有。可以在 gRPC 相关的 metrics 中和 GC - GC tasks 中观察到。
Do GC 阶段:每个 TiKV 自行检测 PD 记录的 safe point 是否更新,如果更新会执行 GC 操作(不同版本行为有差异),与此同时 GC leader 可以继续触发下一轮 GC,因此该阶段的执行过程和其他阶段是异步的,可以通过 TiKV - Details 页面的监控指标判断是否在该阶段:
- 关闭 compaction filter 时,通过 GC - GC Tasks 中的 total-gc 判断
- 开启 compaction filter 时,通过 GC - GC in Compaction Filter 判断
- 无论是否开启 compaction filter,都可以通过 GC - GC Speed 判断
常见 GC 问题
- 主要现象
- safe point 长时间不推进
- Drop table 后磁盘空间一直没有回收
- 可能原因
- gc_life_time 等变量格式错误
- 未提交的长事务 block GC
- 某些 service 的 safe_point block GC
- Resolve Locks 失败
- 将 GC life time 从一个较小的值调大
- GC 运行很慢但正常
- gc_life_time 或 gc_run_interval 等变量设置过大
- 问题排查
检查 GC leader 日志是否有相关报错,判断可能的原因,以下面几种情况的报错为例:
Case1:报错 Failed to parse duration "time: unknown unit "min"in duration"10min"“
参数格式错误,误将 gc_life_time 改成了 10min,应改成 10m
Case2:报错 gc safepoint blocked by a running session
未提交事务 block GC,通过 show processlist 或 information_schema.cluster_processlist 找到 block session。
Case3:报错 there's another service in the cluster requires an earlier safe point
某些 service 的 safe_point block GC,通过 pd-ctl service-gc-safepoint 找到 block service。
Case4:报错 resolve locks failed
通常是 Region unavailable 引起,通过 grep -E "gc_worker|range_task" tidb.log 查询相关报错日志,排查 Region unavailable 原因。
Case5:日志出现 last safe point is later than current one. No need to gc
调大 GC life time 后,新一轮 GC 时 safe point 被重新计算,得到一个比上次 GC 的 safe point 更早的时间,因而无需进行 GC,这种情况不需要处理。
GC 对性能的影响
如果监控观察到 Duration 出现周期性抖动,并且与 GC 运行周期保持一致,可以判断 GC 对性能产生了影响。
5.0 版本默认开启 compaction filter 后,GC 对性能的影响明显下降,当出现类似问题,先检查 compaction filter 是否开启。对于 4.x 版本,可以尝试设置 GC 流控减少对性能的影响。
注意:v5.1.3/v5.2.3/v5.3.0 版本修复了 compaction filter GC 工作机制和 batch client 层的多个 Bug ,建议升级到较新的 release 版本后再开启 compaction filter。
注意事项
当遇到需要恢复误删除数据或调查数据损坏问题(如数据索引不一致)等情况时,可能要临时调大 gc life time 避免历史数据被清理,例如
update mysql.tidb set variable_value = "1000h" where variable_name = "tikv_gc_life_time"set @@global.tidb_gc_life_time = "1000h"
处理完问题后,不要忘记将变量修改回之前的值,避免留存过多的历史数据对业务查询性能造成影响。