LiveMe x TiDB丨单表数据量 39 亿条,简化架构新体验
作者:张龙
近些年,由于互联网的快速发展以及线上需求的爆发,直播在国内已经成为一个非常成熟的商业模式。在娱乐、教育、办公等场景中涌现出许多优秀的视频直播产品。随着国内市场竞争日益白热化,加之企业出海渐成趋势,越来越多的直播公司选择走出去,寻找新的海外直播市场,借鉴国内成熟的产品、运营以及商业模式,让全球的用户都用上中国人创造的产品,LiveMe 便是成功的出海直播产品之一。
LiveMe 是一个全球直播和社交平台,于 2016 年 4 月推出。LiveMe 的产品功能包括 H2H、多人聊天、虚拟形象直播、蹦迪房等,它使用户能够随时随地直播、并观看其他精彩的直播以及与世界各地的朋友进行视频聊天。目前 LiveMe 已在全球积累了超过 1 亿用户和超过 300 万的主播。它已成为美国最受欢迎的社交应用程序之一,并已在 200 多个国家和地区推出。
业务痛点
与其他行业出海一样,直播产品的出海也面临着许多全球化挑战。如各地的合规监管、本地化运营、持续创新、政治文化差异等,都为直播产品出海带来巨大挑战。而在出海的过程中,底层的技术能力帮助 LiveMe 在成本节约、用户增长、金融风控、提升研发效率等方面不断实现精细化运营与业务创新。
经过了多年的沉淀,LiveMe 在业务上已经形成了线上微服务主导,线下计算中心主导的技术架构。线上业务是通过 Go 语言开发的一套微服务架构,每个服务根据不同业务特性具有自己独立的存储。线下业务是由数据研发团队来维护,通过 sqoop 和 MySQL Binlog 同步等方式从数据库层面抓取数据到数据仓库,完成一系列业务相关的支持。
这套业务架构中线上业务主要面临着以下痛点:
第一,虽然完成了微服务分库的设计,每个服务都有自己独立的数据库,但是每个业务中又存在很多业务上的大表,都存在 MySQL 分表的现象。在典型的分表场景中,数据库表会按照用户的 UID 尾号经过 MD5 后分到 256 张表,但是日积月累后又需要再根据时间日期做一个垂直的分表,导致数据库表无法完成聚合查询,再加上跨时间段的分表需求,很多场景无法满足线上需求。
第二,对于分析型业务数据而言,需要保证数据的实时性,并保留数据细节。实时的数据分析,可以在业务上更快做出决策,例如在一些活动运营场景中,业务团队需要快速从各个数据维度来分组统计观察活动效果;在金融相关风控业务中,需要根据各个维度快速聚合来判断各项数据是否达到风控模型的阈值。如果使用离线计算的方式,数据的实时性根本无法得到保证;此外,经过离线计算或者实时计算过的数据,如果用户反馈数据有问题,需要查看数据的细节也很难实现。
第三,各种精细化运营需求,例如推荐、个性化运营等场景不断增加,对于数据的实时要求越来越高。因此,LiveMe 急需一种更简单,同时让线上线下业务做好平衡的方案。
此时,如果 LiveMe 继续选择大数据技术栈解决痛点就会面临以下挑战:1)大数据技术栈的架构非常复杂,中间件过多;2)需要额外的技术栈学习成本,比如如果使用数据同步,就需要 sqoop、scala、kafka 等中间件,会大幅增加整个业务的复杂性;3)希望线上业务以及架构非常简单,能够简化到普通开发人员只要能够 CRUD(增加(Create)、读取(Read)、更新(Update)和删除(Delete)) 数据库就可以上手开发。
为什么选择 TiDB ?
基于以上业务挑战,LiveMe 经过一系列技术选型后最终选择了 TiDB 数据库。TiDB 的以下特性可以帮助 LiveMe 很好的应对挑战:
- TiDB 的性能大于等于 MySQL ;
- TiDB 的 HTAP 特性能够解决线上大表的问题,在后台或者一些实时分析场景中,其 OLAP 分析能力能够保证实时数据报表;
- TiDB 引入的 MPP 架构分析能力,使得 OLAP 查询速度非常快,这也是 OLAP 数据库架构上的技术方向;
- TiDB 团队有着完善和专业的技术支持,在过程中可以帮助 LiveMe 解决很多问题,在线上大规模使用后也没有后顾之忧。
如何利用 TiDB 实现实时聚合查询
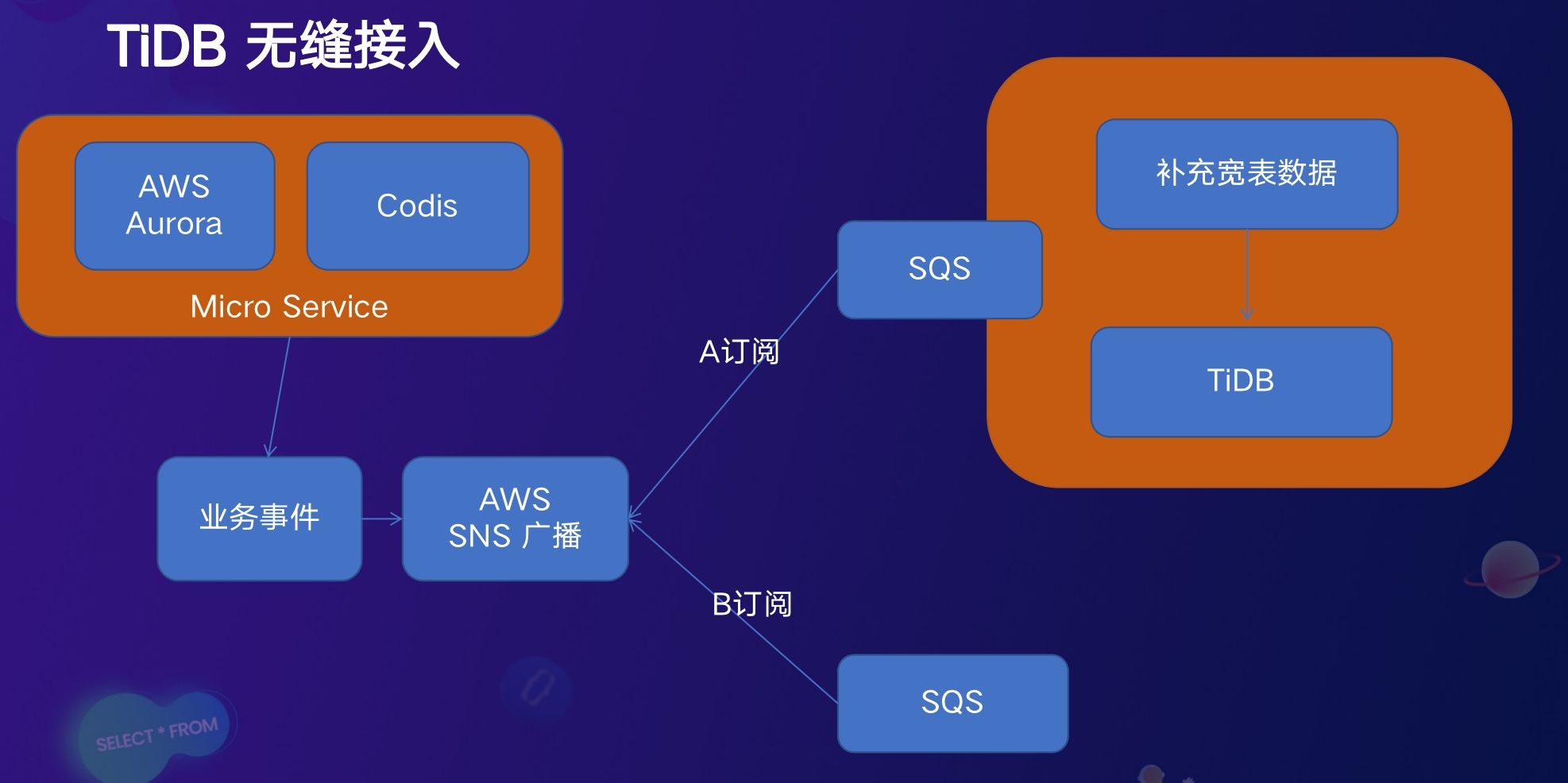
鉴于 LiveMe 的微服务架构,如果将数据源全部替换,工程量大且不能一蹴而就,因此就需要一种兼容性的方案,在保证线上业务不受影响的同时也能使用 TiDB 的特性来解决 LiveMe 的业务痛点。因此,对于需要聚合查询的业务, LiveMe 通过消息队列广播的方式,在业务层订阅相关事件再补充业务侧需要的宽表信息写入 TiDB,基于 TiFlash 就可以做到实时的运营报表。业务开发人员只需要编写对应的 SQL 查询,就可以轻松完成需求。没有了复杂的 ETL 过程,大大简化了开发流程。
对于业务数据, LiveMe 使用 AWS SQS 消息队列,相比 Kafka 的优势在于每条数据都是原子性的,每条数据都可以用来做幂等重试,来保证数据的最终一致性。目前,这套技术方案已经支撑了 LiveMe 的活动运营和金融风控等多个业务场景,满足了 LiveMe 对于线上大量数据实时聚合查询的要求。
如何使用 TiDB 简化技术架构
LiveMe 有一个类似朋友圈功能的场景,这个业务中存在两个技术难点:第一是对于数据的无限量增长存储如何实现扩容;第二是数据的冷热分离,这又涉及到数据成本的问题。
以用户发 Twitter 的场景举例:如果用户发了一条 Twitter,它会写入到自己所有的关注列表,比如有 100 个粉丝,就写入 100 条,如果有 10 万粉丝就需要写入 10 万条数据,这是一个典型的写扩散场景。这个场景带来的效果是数据爆炸半径非常大,如果某流量网红发一条 Twitter ,数据写入量会非常大,因此需要一个能够接近于无限扩容的存储机制才可以实现这个场景。
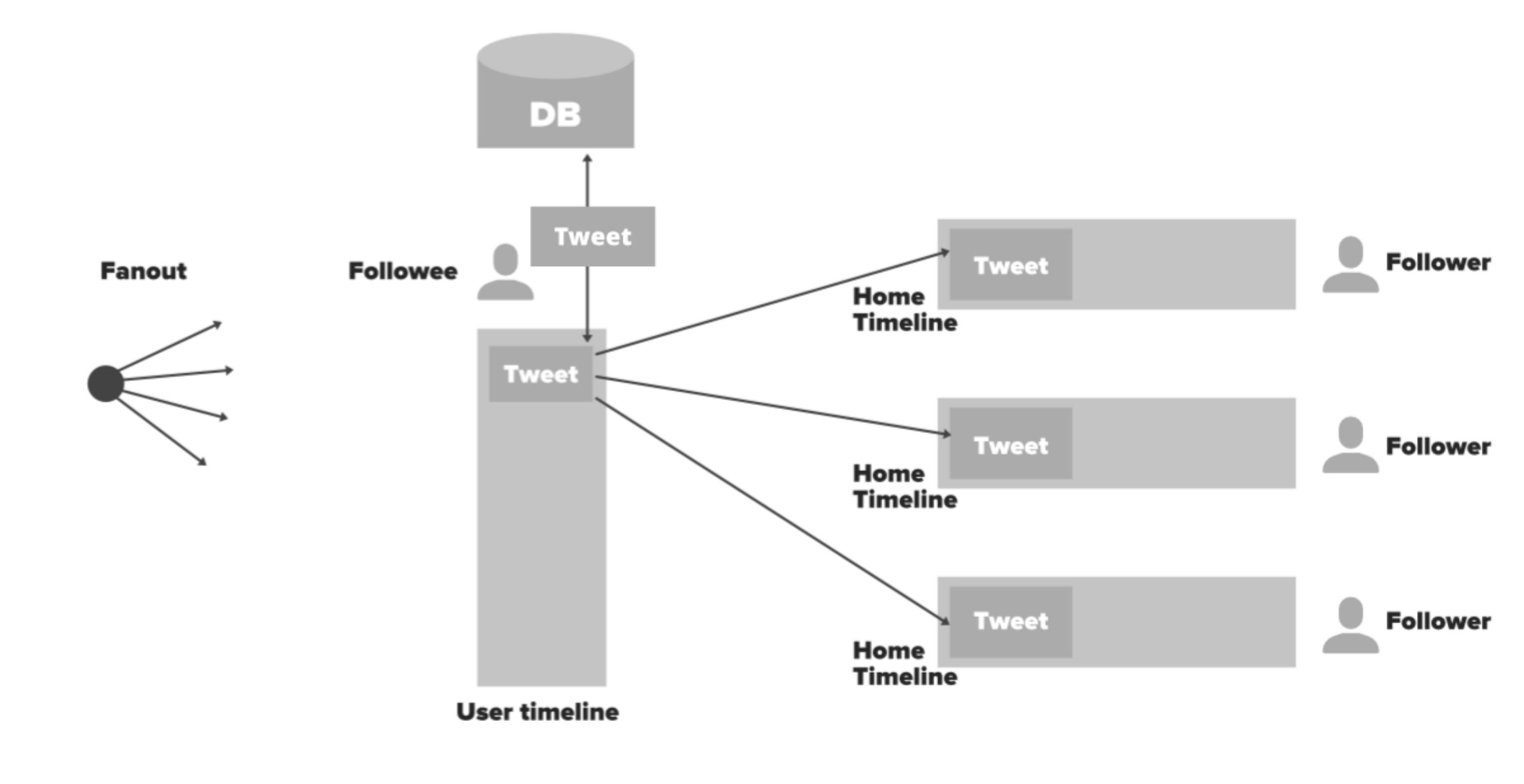
Twitter 的技术实现
Twitter 是通过维护一个 redis-cluster 来解决 feed 分发的存储。LiveMe 的技术团队也想到使用这种技术架构,技术团队经过选型考虑使用 codis 集群来做存储,但通过对成本的考量,认为这个方案是不可行的,大量的 feed 冷数据存储在 codis 这样的内存密集型数据库中,成本非常高。因此,技术团队面临的挑战是如何用低成本的方式去实现一个写扩散的场景。
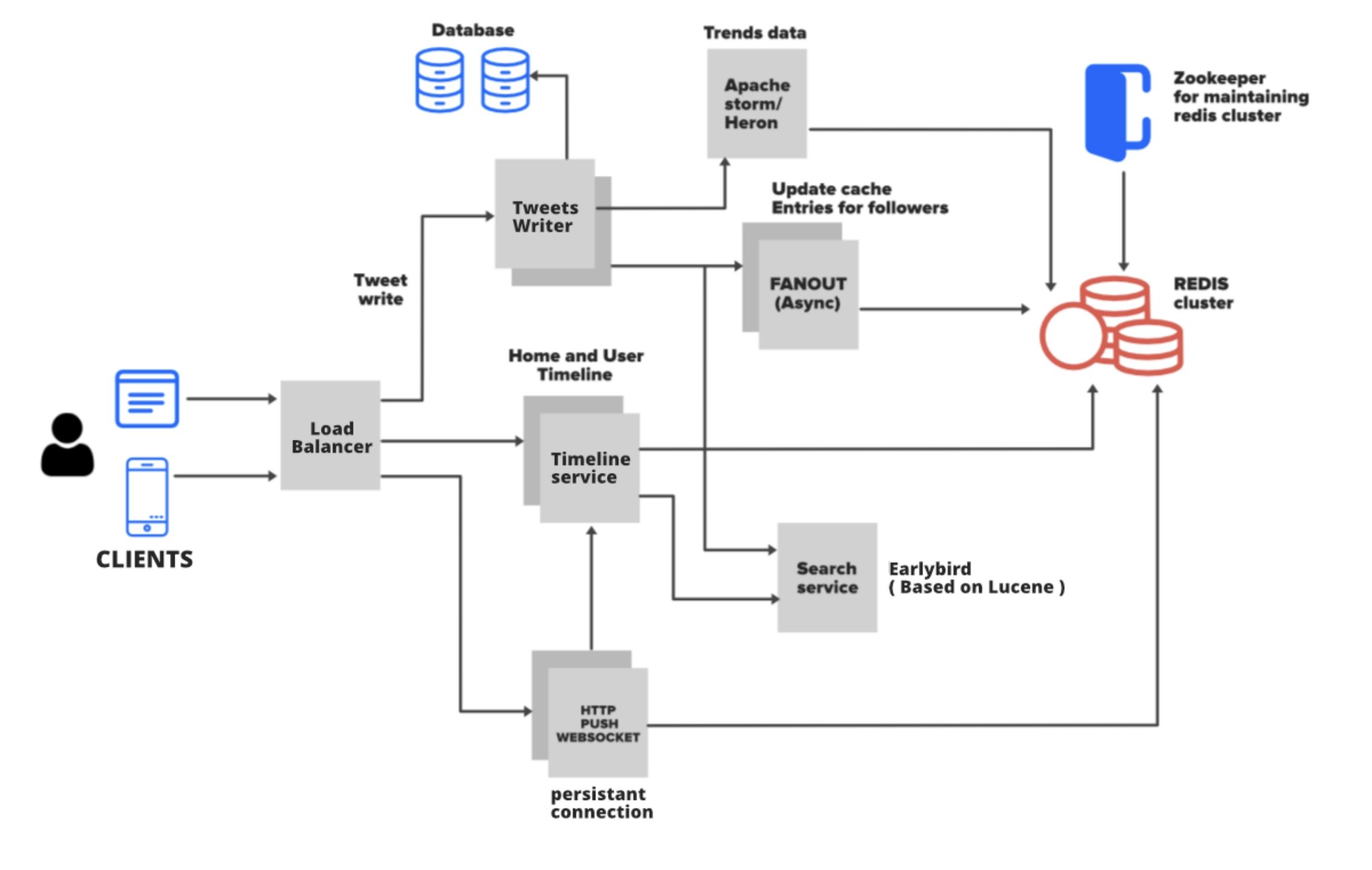
Twitter 的解决方案
基于 TiDB 解决方案,LiveMe 技术团队在上述写扩散场景中,把扩散写入的部分替换成了 TiDB,使用一张数据库表来存储所有 feed 的写入关系,比如用户有 100 万粉丝,就在数据库里插入 100 万条数据。基于 TiDB 的分布式数据库特性,帮助 LiveMe 简单高效地解决了数据增长扩容问题。
基于此技术架构,技术团队简化了一个典型的 redis 缓存设计问题,热数据放在 redis 中,用 mget 来获取。冷数据放在 TiDB 中,用 select in 查询,这样做数据冷热区分就非常容易,甚至可以实现一个简单的布隆过滤器来了解哪些数据在热数据,哪些数据在冷数据里。以此减少无效数据的回源,更高效获取数据。
LiveMe 的朋友圈功能基于 TiDB 的分布式存储特性进行技术改造后,feed 表从 2021 年中旬上线至今已经达到数十亿数据写入,现在的数据量单表 39 亿条。因为这些数据是永久保留不会删除的,所以该数据也会一直增长。
未来规划
未来, LiveMe 将会继续尝试 TiDB 在更多业务中,一方面会做数据库管理开发;另一方面将对于强事务依赖交易型的业务尝试使用 TiDB,为直播电商场景做技术储备。